0%
0%
Careless WSPR
A desultorily executed Weak Signal Propagation Reporter beacon.
 ziggurat29
ziggurat29Become a Hackaday.io member
Already have an account? Log in.
Just one more thing
To make the experience fit your profile, pick a username and tell us what interests you.
Pick an awesome username
hackaday.io/
Your profile's URL: hackaday.io/username. Max 25 alphanumeric characters.
Pick a few interests
Projects that share your interests
People that share your interests







 Al Williams
Al Williams

 Charlie Smith
Charlie Smith
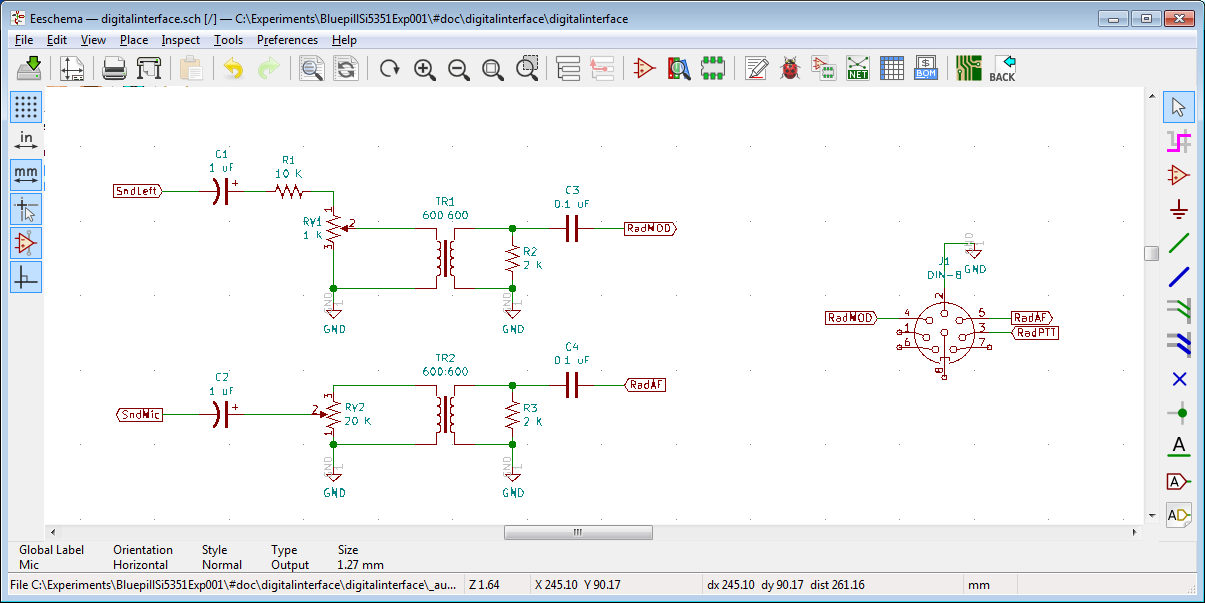
Some possible answers: wsprnet org is ok with balloon flight wspr beacons etc to extend the wspr format for other purposes like some form of telemetry. Special callsigns are used to differentiate. I happen to be one of their admins.
Better location information is available in the database with a callsign, so better position data does not depend on only 4 Maidenhead characters. Mostly 6 are used. For higher than HF frequencies more might be relevant. There are also other ways to combine a callsign with even more detailed locator information.
Feel free to contact me when other codes are needed, there might be ways indeed.
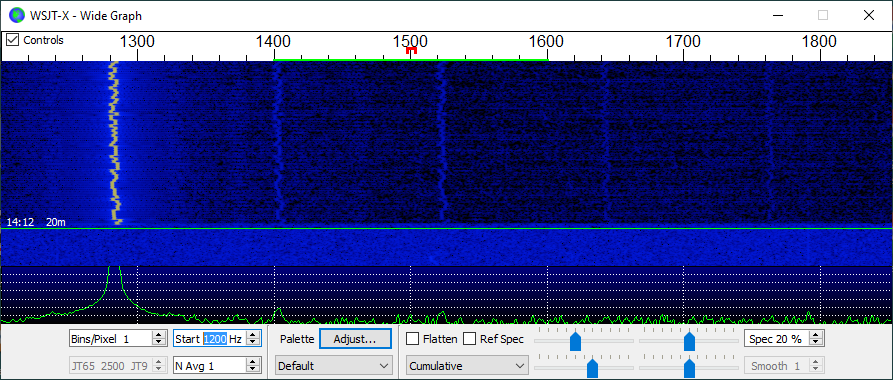
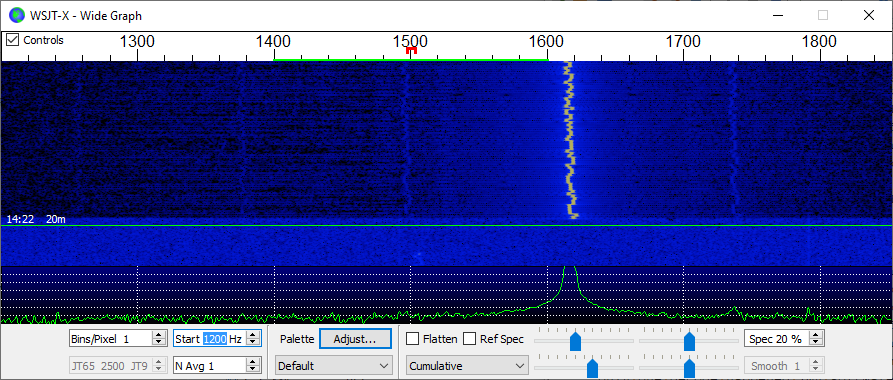
I do not understand why you would want to find the frequency from the waterfall, you can use a frequency counter or the database at wsprnet org to have it to the last Hz.
Erwin
PE3ES
73