 Alexander Hagerman
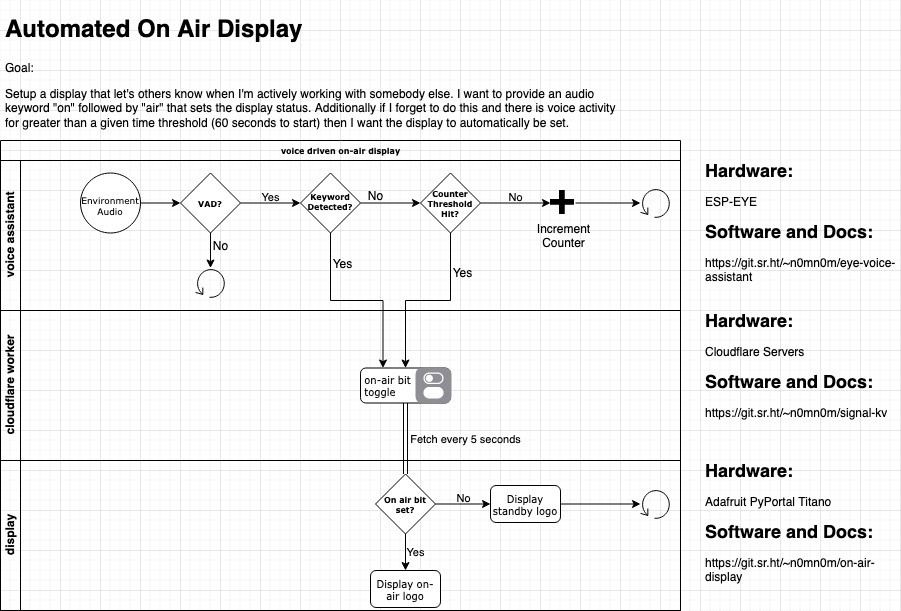
Alexander HagermanMany of us work in environments where it's useful to let others know that we are head down busy on a project or collaborating with somebody else. To help with this I setup a display that shows the Jolly Wrencher on a green or red background indicating whether I am busy or free.
For this project I trained and deployed a Tensorflow Lite model on ESP-EYE that listens for a wake word (visual) followed by a command (on/off) to set that signal bit managed by a Cloudflare Worker that is then read from by the display (PyPortal) setting the appropriate screen.



 andrew.powell
andrew.powell
 Andrew & Ben
Andrew & Ben

 Adam - Meshnet
Adam - Meshnet