 Eric Hertz
Eric HertzThis project has been an adventure of the most ridiculous sort...
At the time I started this project-page I planned on emulating an 8088 in an AVR, so the AVR could be a drop-in replacement for the original CPU in an IBM PC/XT clone. The discovery that the original 8086 ran at something like 0.3MIPS, and the knowledge that AVRs can run at 20MIPS gave me the idea that maybe it would be possible to emulate an (even slower) 8088 in an AVR at usable-speeds, and maybe even run faster than the original.
I spent quite a bit of the lead-up time learning the (then, to me) "black-box" that x86-architecture has been to me for decades. This was aided by the fact that the original technical references for the 8088/8086 go into quite a bit of detail explaining *why* they made decisions they made in this (then new) design, in comparison to Intel's earlier processors, like the 8085, which are much more similar to the Atmel AVRs I'm so familiar with. E.G. Why do they use "segments" in the x86 architecture? And what the heck does 33:4567 mean, as an address, anyhow? (One of the many things I couldn't wrap my head around in previous endeavors trying to understand the x86 architecture).
From there, I went on to [re]assemble my PC/XT clone from parts that'd been poorly-stored for years in various boxes with other scrap PCBs and no anti-static bags. That endeavor, alone, was utterly ridiculous; leading me to sleep upright on a tiny spot on my couch for days, if not weeks; home filled with open boxes, cat sleeping angrily under the TV. And some completely unexpected, and amazing, results in the process. Including meeting someone who emailed to me exactly the (very rare) information I needed within 3 hours of my contacting an email address found in a forum post written 17 years earlier. (whoa!). Also, the surprising discovery that PNPs' emitters can be connected to the ground-rail and make for a [only slightly-differently]-functional circuit than the NPN I'd intended. Also, some "fun" with computers that seemingly-consciously refused to be of assistance (one, quite literally, glaring back at me in contempt).
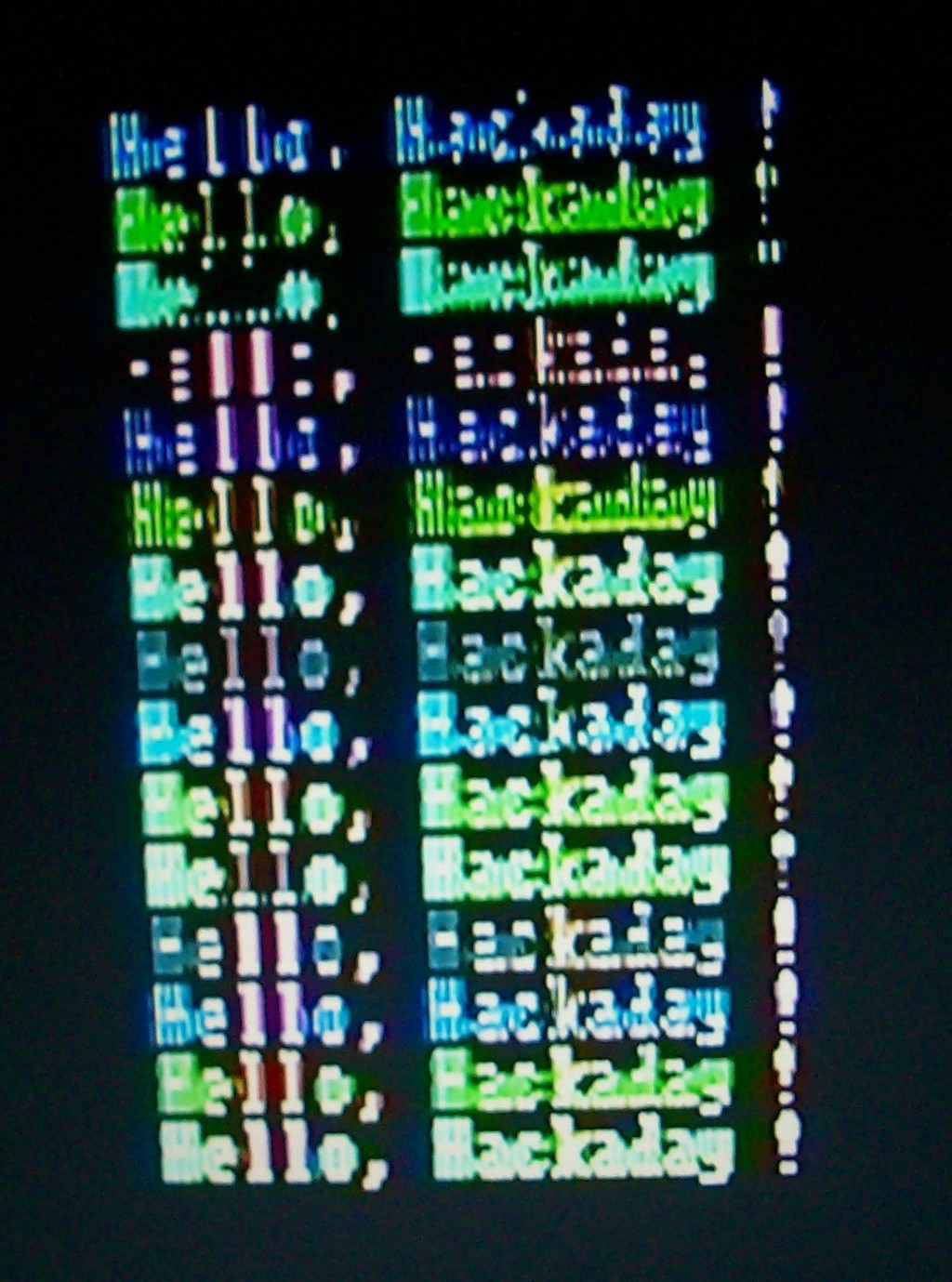
As it stands, I've finally got the PC/XT clone assembled and running in an ATX case, and, with the help of a fellow HaDer, even installed my very first x86-Assembly program as a BIOS-Extension ROM, that it boots straight into!
---------
Still, at this point in the story, I'd been planning to emulate the 8088/86 instruction-set within my AVR... And I'd done quite a bit learning about the instruction-set...
"That's a pretty big lookup-table, nevermind all the code. But I have *some* ideas about how to shrink it... maybe at the cost of execution-speed."
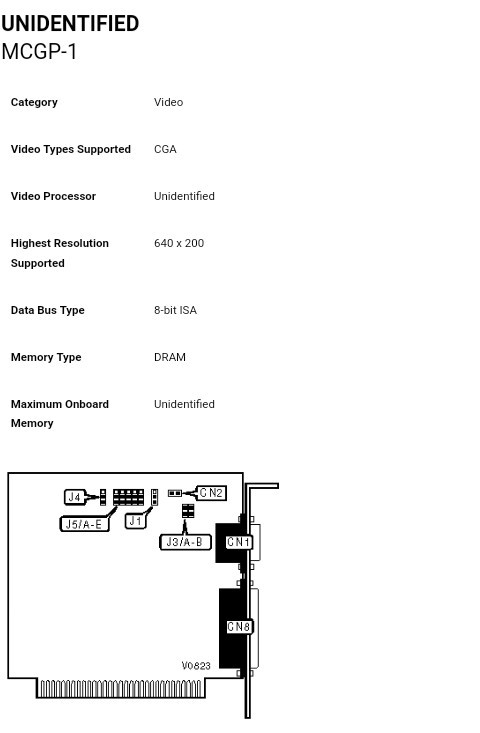
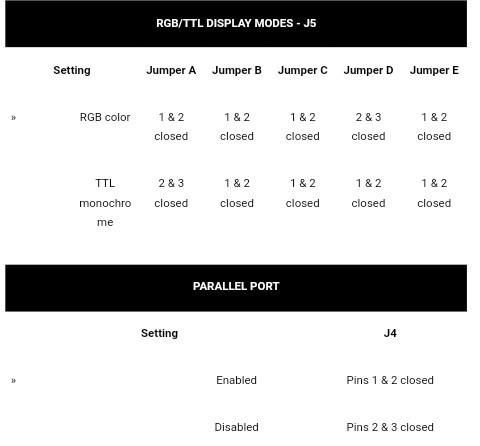
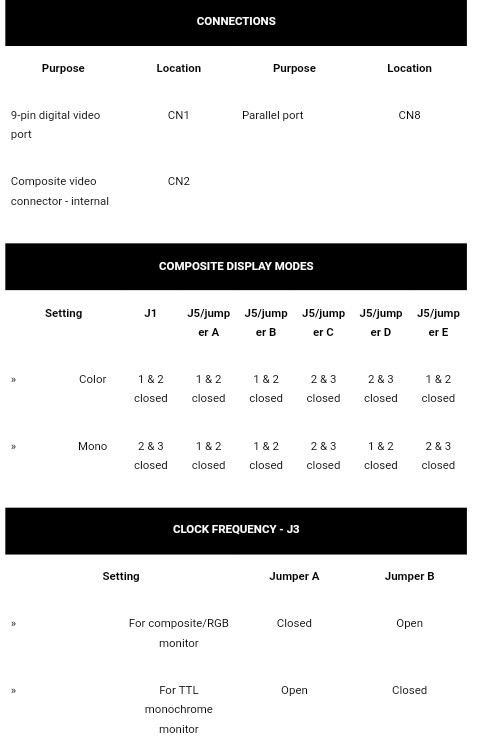
Also, at this point in the story, I started considering other ideas, such as emulating *hardware* within the AVR... Thanks to some other projects 'round HaD. E.G. Why use the 8250 UART, on an ISA card, when the AVR has a USART built-in? I did the math, and discovered that writing a byte to the AVR's USART transmit-register would take ~3AVR instruction-cycles, whereas doing the same with the 8250 could take more than ten times as long! Similarly, if the 8088's 8KB BIOS ROM was stored within the AVR, rather than on the 8088's "bus-interface", execution of the BIOS (the Basic Input/Output System, used for *way* more than just POST!) could be *significantly* faster.
------------
This is the point in the story where I take a step back and start thinking about what led me here in the first place... not only in terms of what I'd discovered *during* the project, but what led me to start this project...? And I realized, the goal from the beginning, from *years* before starting this "project," was to use an otherwise now-outdated (some might say "useless") system's motherboard and peripherals with the processor-architecture I'm already familiar (AVRs).
So, emulation of the x86 instruction-set/architecture was never really in the original goals... I got sidetracked (what? Me?!). But it has been a useful learning-experience....
Read more »









 Samuel A. Falvo II
Samuel A. Falvo II
Wow ! That's very impressive !
You wrote that the original technical references explain the various design decisions and answer a lot of 'why did they do that' questions. Could you share the references so we can also educate ourselves ? Thanks :-)