 Yann Guidon / YGDES
Yann Guidon / YGDESPRELIMINARY
May 8th, 202: It only got started.
Class for comparison : i486, i586 (no MMX), i960/i860, MIPS R3000 or R5000, SPARC V7/8 or LEON, RISC-V, ARM Cortex-R...
- Type : embedded safe/secure, 32-bit application processor for medium performance
- 32 bits per instruction
- 32-bit wide words
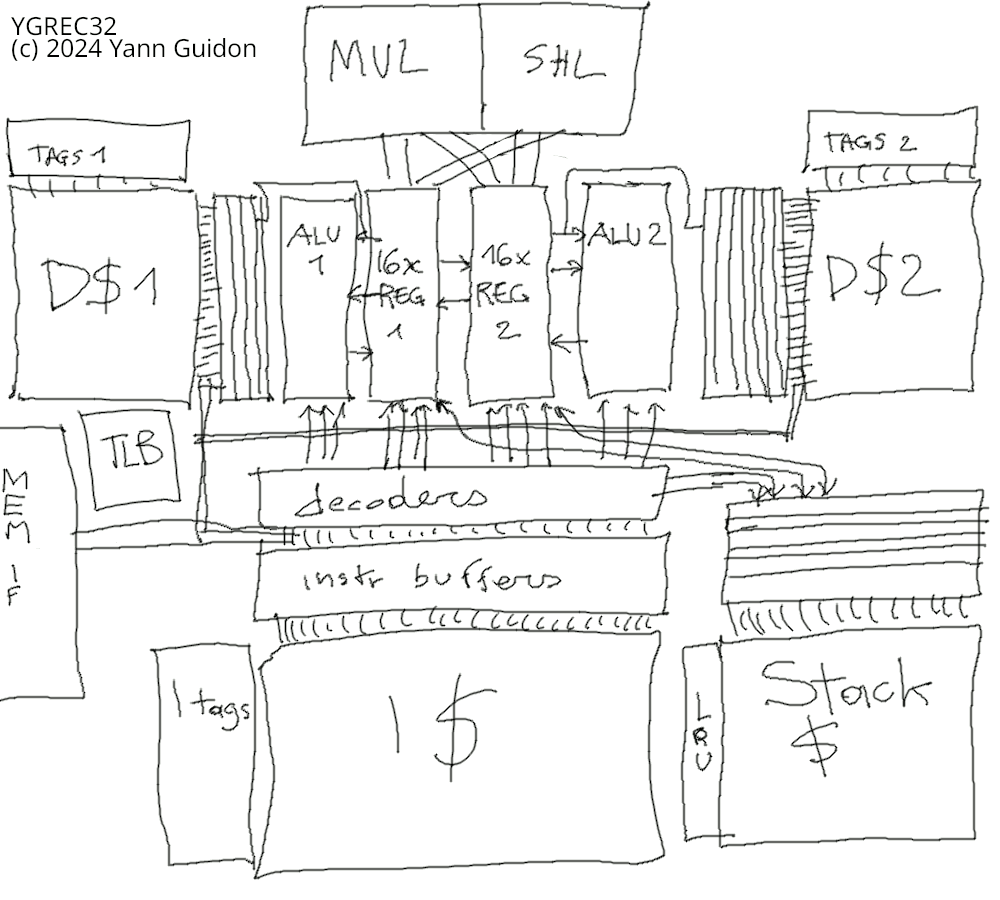
- 2 "globules" with 1 ALU 16 registers and a cache block each.
- register mapped memory
- CDI model: separate addressing spaces for Control (stack), Data and Instructions.
- 28 bits for instruction pointers, 2^27 instructions/512MiB of code per module.
- Flexibility: Implemented as 1 long/fast pipeline or 2 shorter/slower parallel pipelines.
- Multitasking suitable for Real Time/Industrial OS, light desktop or game console workloads.
- Heavy computations are offloaded to suitable coprocessors.
- Tagged control stack
- Some high-level single-cyle opcodes provide basic control structures.
- Resilient, safe and secure by design
- Need 64 bits or SIMD ? Use its big brother the #F-CPU FC1 (tba)
- Too overkill ? Use a microcontroller like the #YASEP Yet Another Small Embedded Processor (16/32 bits) or even the #YGREC8(8 bits).
- Spoiler alert : it is not designed with Linux-friendliness in mind.
Rationale:
For now I'm only collecting the ideas. Several years ago I considered a streamlined YASEP with only 32-bit instructions but it would have broken too many things. The YASEP (either 16 or 32 bits) resides at a particular sweet spot but can't move significantly outside of it. OTOH a 32-bit mode for F-CPU would have been interesting but still too ambitious : F-CPU is a huge system so even implementing a simpler subset implies already having the whole already well figured.
So YGREC32 is not really a cleaned-up YASEP. The use of a dedicated control stack does not fit well in the YASEP which will remain a "microcontroller". The YGREC32 is an application processor for multitasking environments that will run user-supplied code. It is still suitable for real time but not heavy lifting. It could be simultaneous-multithreaded for even better efficiency. Yet YGREC32 binaries would be easily executed by FC1 with little adaptation since it's mostly a subset, with half the globules and smaller words.
A redesigned, pure 32-bit processor is a clean slate where I can develop&experiment with several methods such as #A stack. It becomes the first architecture to explicitly implement and develop the #POSEVEN model. It will be a shaky ride but hopefully it will help further our goals.
Logs:
1. First sketch (and discussion)
2. .
3. .
4.
......
 Erik Piehl
Erik Piehl
 Kannagi
Kannagi

 Szoftveres
Szoftveres