My goal with this project is to learn FPGA design by implementing an original Nintendo Entertainment System (North American, not the Famicom) in Verilog. I'm still working out details of implementation (A/V peripherals, memory, user interface, etc), but I have a few design choices already made (mostly purely arbitrarily).
Language: Verilog. No real reason for this choice, I used VHDL in college a bit and thought Verilog seemed neater.
Hardware platform: I'm using the Mimas V2 FPGA development board from Numato Lab (http://numato.com/mimas-v2-spartan-6-fpga-development-board-with-ddr-sdram/). I mostly bought it because it was cheap and had a bunch of peripherals baked in already. It uses a Xilinx Spartan 6, which seems more than big enough for now, and has some nifty things built-in like a 512 Mb DDR RAM, USB support for programming and communication, and VGA and audio outputs (along with the standard buttons, switches, LEDs, and GPIOs). I've already run into at least one glitch, which I'll discuss later, but overall I've been pretty pleased with it.
Software platform: I'm using the ISE Webpack IDE from Xilinx as the synthesis, implementation, simulation, and compilation toolchain. Numato also has a custom executable for downloading the generated FPGA configuration file to the board through USB, which is handy. ISE has given me some trouble already, I think mostly due to its lack of Windows 10 support, but I've figured out workarounds to most of them and I'm too lazy to do anything about it. I've also written a few supporting programs for communication with the board in Java (using NetBeans, because reasons).
Shortly, I'm going to start uploading build logs to document what I've done so far (as of this writing, I've implemented the CPU and am doing some testing of it now). I hope to pretty thoroughly explain what I'm doing in each part, both so people can check me on it, and so I don't forget in like 6 months as usual.
If anybody sees this and notices any errors or Verilog/FPGA noob mistakes, please don't hesitate to let me know. I'm in this to learn things, and while I've tried to take care to do things in a semi-up-to-standard way, I have probably definitely 100% done silly things, and would like to correct them if possible.
Enjoy reading through this! All code is hosted on GitHub, there should be a link to it on this page somewhere.
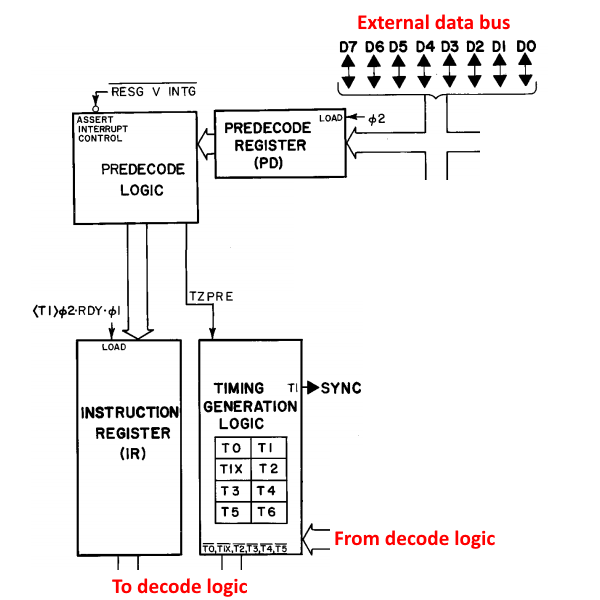
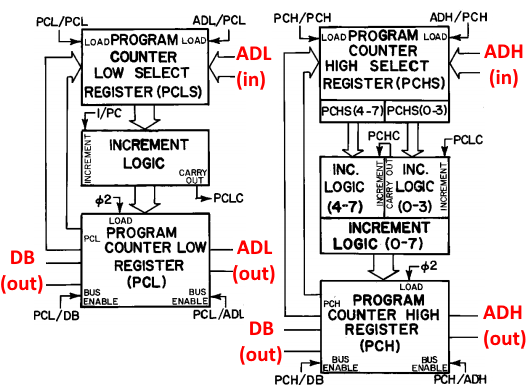
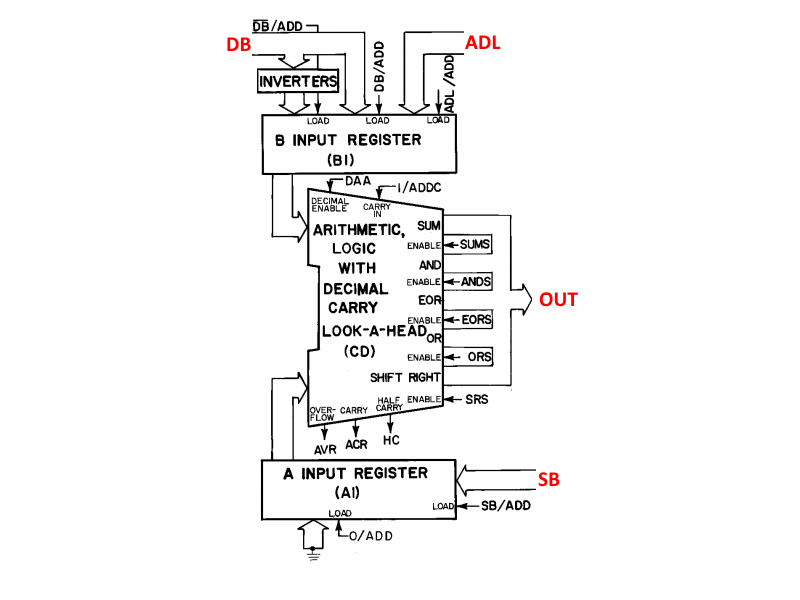
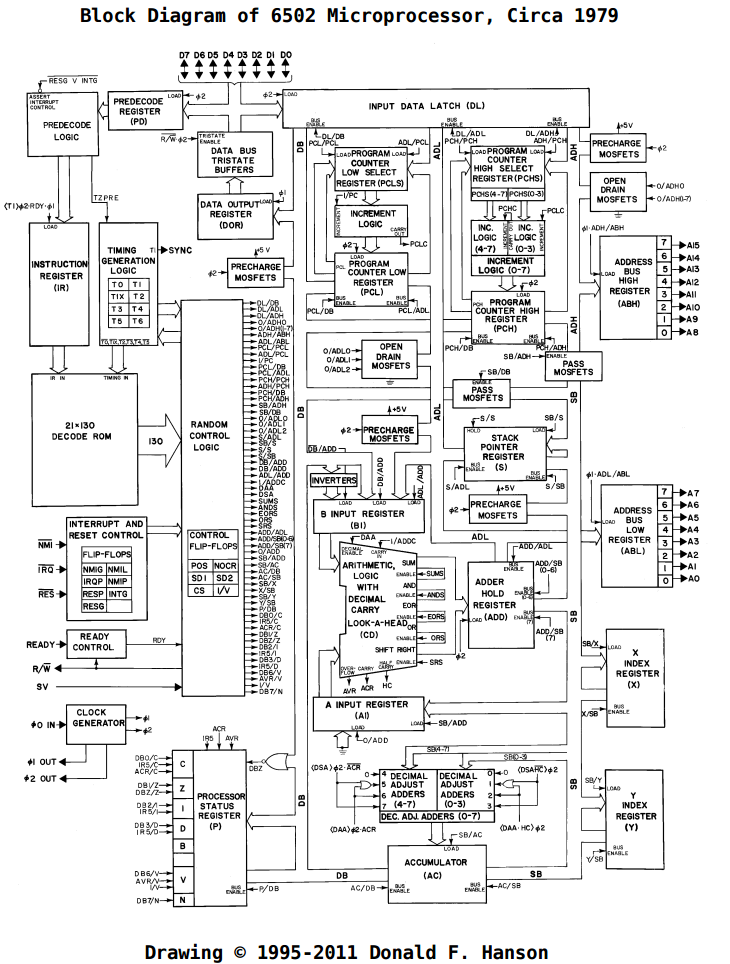 Some basics: The 6502 is an 8-bit processor, with a 16-bit address space. It has 6 internal registers (3 special purpose – the program counter, status register, and stack pointer – and 3 general purpose – X, Y, and the accumulator). The registers are linked to the various parts of the CPU through 2 main internal buses (the Data Bus and the Special Bus, DB and SB in the block diagram), along with 2 buses dedicated to shuttling the low and high bytes of the address around (ADL and ADH in the block diagram). There are also interconnects between buses so you can connect them together and get data wherever it’s needed. The ALU is pretty central in the design: besides the usual operations on external data, it’s also used for internal purposes like temporarily storing data and addresses while other data is being fetched as well as computing addresses for some of the more complicated addressing modes. All of this is coordinated and controlled via the opcode decoder, which decides what to do on each cycle of each opcode.
Some basics: The 6502 is an 8-bit processor, with a 16-bit address space. It has 6 internal registers (3 special purpose – the program counter, status register, and stack pointer – and 3 general purpose – X, Y, and the accumulator). The registers are linked to the various parts of the CPU through 2 main internal buses (the Data Bus and the Special Bus, DB and SB in the block diagram), along with 2 buses dedicated to shuttling the low and high bytes of the address around (ADL and ADH in the block diagram). There are also interconnects between buses so you can connect them together and get data wherever it’s needed. The ALU is pretty central in the design: besides the usual operations on external data, it’s also used for internal purposes like temporarily storing data and addresses while other data is being fetched as well as computing addresses for some of the more complicated addressing modes. All of this is coordinated and controlled via the opcode decoder, which decides what to do on each cycle of each opcode. 
 spudfishScott
spudfishScott
 2-Zons
2-Zons
 kaimac
kaimac