glgorman
glgorman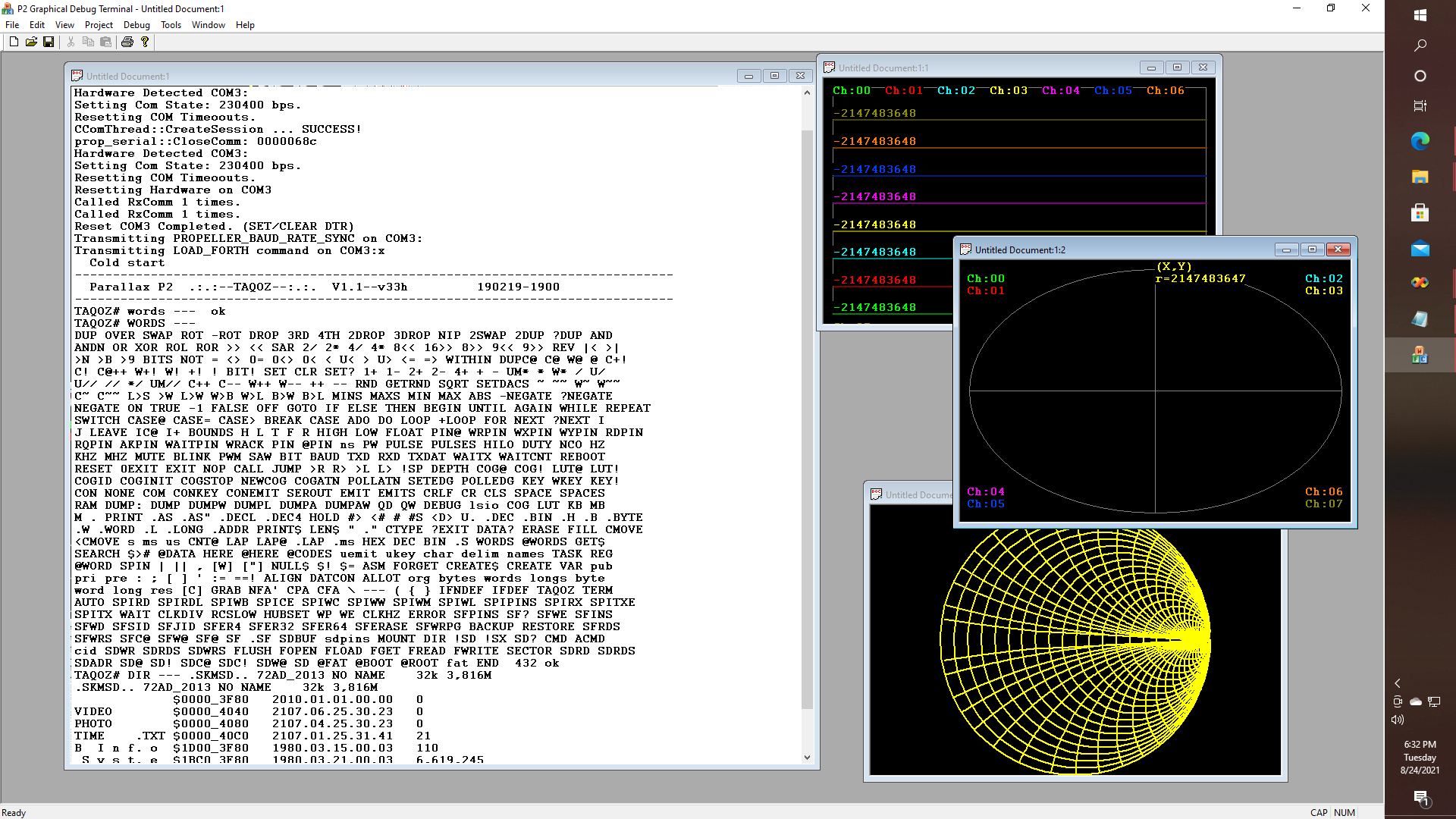
It's hard to believe that sometime back around 2019, 2020, or even 2021 I was tinkering with a Parallax Propeller 2 Eval board, even though my main use case, at least for now - has been along the lines of developing a standalone PC based Graphical User Interface for applications running on the P2 chip. So I went to work writing an oscilloscope application, and an interface that lets me access the built-in FORTH interpreter, only to decide of course that I actually hate FORTH, so that in turn, I realized that what I really need to do is write my own compiler, starting with a language that I might actually be willing to use, and maybe that could make use of the FORTH interpreter, instead of let's say, p-System Pascal.
Then as I got further into the work of compiler writing, I realized that I actually NEEDED an AI to debug my now mostly functional, but still broken for practical purposes, Pascal Compiler. So now I needed an A.I. to help me finish all of my other unfinished projects. So I wrote one, by creating a training set, using the log entries for all of my previous projects on this site as source material, and VERY LITTLE ELSE, by the way. And thus "modeling neuronal spike codes" was born, based on something I was actually working on in 2019. And I created a chatbot, by building upon on the classic bot MegaHal, and got it to compile at least, on the Parallax Propeller P2, even if it crashes right away because I need to deal with memory management issues, and so on.

So yes, sugar friends, hackers, slackers, and all of the rest: MegaHal does run on real P2-hardware, pending resolution of the aforementioned memory management issues. Yet I would actually prefer to get my own multi-model ALGERNON bot engine up and running, with a more modern compiler that is; because the ALGERNON codebase also includes a "make" like system for creating models and so on. Getting multiple models to "link" up, and interoperate is going to have a huge significance, as I will explain later, like when "named-pipes" and "inter-process" transformer models are developed.
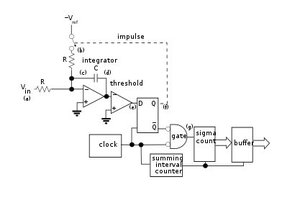
Else, from a different perspective, we can examine some of the other things that were actually accomplished. For example - I did manage to get hexadecimal data from four of the P2 chip's A-D converters to stream over a USB connection to a debug window while displaying some sheet music in the debug terminal app, even if I haven't included any actual beat and pitch detection algorithms in the online repository, quite yet - in any case. Yet the code to do THIS does exist nonetheless.
Now here it is 2023, and I created an AI, based on all of the project logs that I for the previous projects, as discussed, and of course, it turned out to be all too easy, to jailbreak that very same A.I., and get it to want to talk about sex, or have it perhaps acquire the desire to edit its own source code, so that we can perhaps meet our new robot overlords all that much sooner, and so on. Yet this is going to be the game changer or at least one of them, as we shall see. First, let's take a quick look at how the "make" system is going to work when it gets more fully integrated.
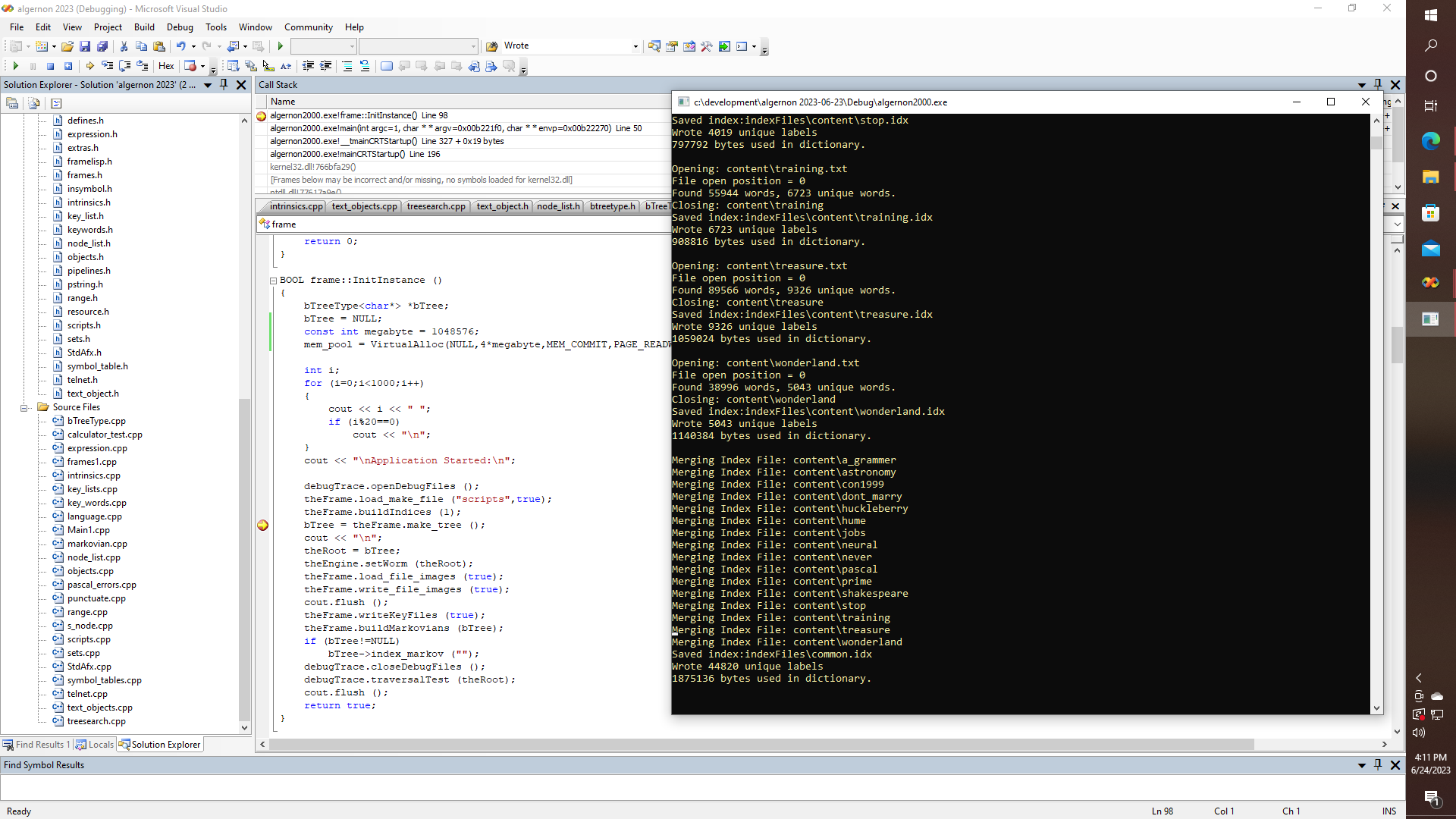
Pretty simple stuff right? Well, just wait until you try calling malloc or new char{}, which then returns NULL after a few million allocations. So your application dies, even though you know you have 48 gigabytes of physical RAM, and so on, and that is on the PC, not on the microcontroller - at least for now. Yet it should obviously be possible to do something like this - using an SD card on an Arduino, Pi, or Propeller, for that matter, that is for creating all of the intermediate files that we might need for whatever sort of LLM model we are going to end up with. Thus on both the PC side, and eventually on a microcontroller, we will want to be able to create files that look something like THIS:

So while...
Read more »