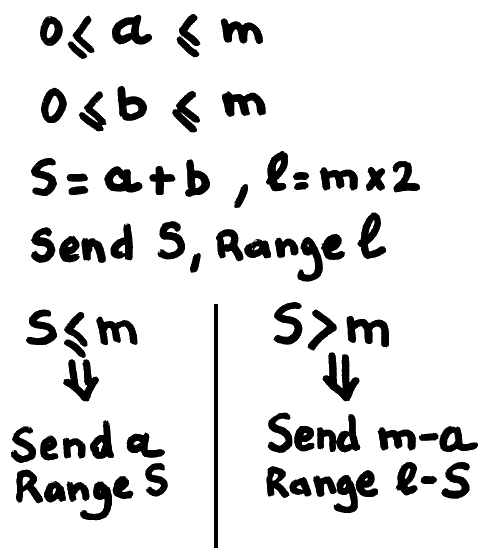
 Yann Guidon / YGDES
Yann Guidon / YGDES20170524: A new generation of 3R algorithms, using the newer #σα code as a mother function, is being developed at #3RGB image lossless compression format.
The Recursive Range Reduction algorithm is a pretty unusual algorithm that compacts (or packs) successive samples of a continuous signal (it is designed for anything DSP-related, not text). It is inherently adaptative, it can extract different features at various scales and it can work where other classic alphabet-oriented (LZx, BWT, RLE...) methods fail. As it uses a different metric of entropy (it does not look at repetitions or probabilities), it's a new tool in the data compression scientist's toolchest.
The applications for the 3R algorithm are pretty "niche" but a smaller, and faster implementation will make it more appealing for low-resources signal processing.
The purpose of this work is to design and implement a new, custom, resilient, high-speed video transmission protocol where a small bandwidth decrease is desirable (vs uncompressed data) as long as latency and complexity are kept very low. A "bypass" mode prevents data from exceeding the original size (which happens quite often).
Lossless sound compression is seriously considered. Other applications are possible, such as data logging of physical measurements (temperature, light, hygrometry, whatever). You'll have to provide your own filter/predictor to pre-crunch the numbers and make them palatable to 3R.
Currently, only the "tree" part of the decoder is publicly available in JS. Hopefully, this work will evolve to a fully portable format for image coding/decoding that is much lighter than a full PNG library.
Funnily, I only discover VESA's DSC (Display Stream Compression) in 2015/9 : www.vesa.org/wp-content/uploads/2014/04/VESA_DSC-ETP200.pdf The 3R algorithm is less efficient but it is really lossless (there is no quantization in the initial design, though there can be in specific cases), uses very little storage or electronic gates, and (unlike VESA's $350 fee) it's Free Software from the beginning ;-)
Logs:
1. First sample source code snippet
2. 3R encoding and hierarchical census data mapping
3. First successful decoding of 3R stream in VHDL
4. Synthesis/place/route results
5. Simplicity
6. Color spaces
7. Publication in Open Silicium
8. Another set of articles in OpenSilicium
9. Another article about the VHDL implementation
10. Project status
11. Design of the bit extraction circuit
12. Plane-filling curve
13. Breakthrough

 The milestones have been finally reached but a lot of work remains before the sound and image compressors finally go live in FPGA.
The milestones have been finally reached but a lot of work remains before the sound and image compressors finally go live in FPGA.
 Hopefully, the VHDL will be published in OS n°18 (april 2016 ?) (done:
Hopefully, the VHDL will be published in OS n°18 (april 2016 ?) (done: 


 Jac Goudsmit
Jac Goudsmit

if yI want to compress a BYTE stream, 8 bit in, 8 bit out, then I should set DEPTH=0 ??
but that doesnt seem to work, so how can I compress a byte wide stream?