 Christoph Tack
Christoph TackProgress
Voice codec
☑ Selection of voice codec : Codec2
☑ Implementing voice codec on embedded platform : esp32-codec2
☐ Making unit test for voice codec
☐ Turning Codec2 into a standalone Arduino library, which will allow for easier integration by third parties.
Audio streaming
☑ Audio playback : Sine output by I²S on ESP32's internal DAC : esp32-dds (direct digital synthesis)
☑ Real time Codec2 decoding and audio output on ESP32's internal DAC : esp32-codec2-DAC
☑ Audio capture (through I²S)
☑ Output sine wave to external I2S Audio codec (i.e. SGTL5000)
☑ Decode Codec2 packets in real time and output them on SGTL5000 headphone and line out. The Codec2 decoding and audio streaming is all done in tasks. The 'loop'-function has nothing to do.
☑ Audio feed-through using SGTL5000 : it took some tweaking to adjust the input audio level to line-in levels of the SGTL5000 and headphone output volume settings. I2S-peripheral works full duplex here, while ESP32 documentation only mentions half-duplex operation.
☑ Real time codec2 encoding analog audio from SGTL5000's line input. Codec packets are printed real time in base64 format to serial port
☐ Audio filtering in SGTL5000, which codec2 should benefit from.
☑ Half-duplex operation : every few seconds the codec switches between encoding and decoding. It decodes packets stored in flash. It encodes audio from the SGTL5000 codec.
☑ Refactoring encoding/decoding of packets. Codec2-engine now has two separate queues for output and two separate queues for input. Semaphores have been removed as they made the code unnecessarily complicated.
Wireless communication
☑ Generating some RTTTL music and transmitting it with the SX1278 FSK-modem on 434MHz. The RSP1A decodes it fine using CubicSDR. It's not very useful, but it's fun. Using PDM, we might even be able to play rudimentary audio.
☑ SX1278 modules using RadioLib : LoRa, FSK and OOK.
☑ SI4463 module using RadioHead : 2GFSK
☑ SI4463 module using Zak Kemble's SI4463 library : 4GFSK in 6.25kHz channel spacing
☑ Adding SI4463 to RadioLib library (basic RX/TX works, but the code needs a lot of clean up)
☑ Adding RSSI readout to SI4463 RadioLib library (in preparation of antenna comparison tests)
☑ Deriving from Arduino Stream class in wireless library + interrupt based. Based on Zak Kemble's library and arduino-LoRa. Abandoning RadioLib. This makes it possible to add existing overhead protocols such as PacketIO or nanopb-arduino (Google Protocol Buffers).
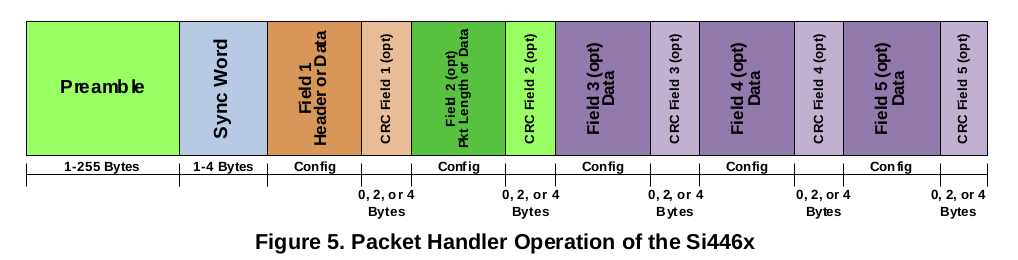
☑ Expanding packet size beyond 128bytes to improve air rate efficiency. This implementation can send packets of 400 payload bytes or more, unlike many other si4463 libraries on github which are limited to 255 or 129 bytes or even less. The implementation can be found here : si4463-stream.
☐ Introducing FX.25 FEC (forward error correction) to reduce packet loss on bad quality links.
☑ Implement this as a KISS modem for https://github.com/sh123/codec2_talkie. Source code on : arduino-kiss.
Audio & wireless combined
The implementation of sending raw audio packets works, but it's not compatible to similar solutions. It's most likely that the further development of audio & wireless combined will be abandoned in favor of a solutions like codec2_talkie or m17-kiss-ht.
☑ One way radio : transmitter station sends codec2 packets, while receiving station decodes them and plays them through the SGTL5000 on the headphone.
☑ Two way radio with PTT : both stations run the same code. When PTT-button is pushed, the station starts encoding audio from line-in of the SGTL5000 and broadcasts them using the SI4463. The other station receives the packets, decodes them, and plays the SGTL5000. The custom main.cpp source file is less than 150 lines long. The remainder of the code consists of reusable libraries.
Security
Implemented using libsodium :
☑ Authenticated key exchange...
Read more »











 Paul Stoffregen
Paul Stoffregen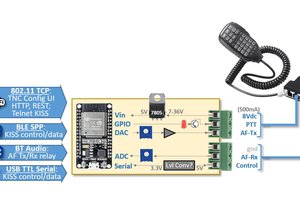
 Ryan Kinnett
Ryan Kinnett
 Fluxly
Fluxly
 Dan Julio
Dan Julio
Reticulum works with any KISS device, as long as it allows for a minimum MTU of xx bytes (I forgot the number).
Anyway: If you want support from the Reticulum creator, you'd better use RNode hardware (https://markqvist.github.io/Reticulum/manual/hardware.html)