Current Hardware:
- 1x RPi 4 w/ 2GB RAM
- management machine
- influxdb, apcupsd, apt-cacher
- 3x RPi 4 w/ 4GB RAM
- 1x ceph mon/mgr/mds per RPi
- 18x RPi 4 w/ 8GB RAM
- 2 ceph osds per RPi
- 2x Seagate 2TB USB 3.0 HDD per RPi
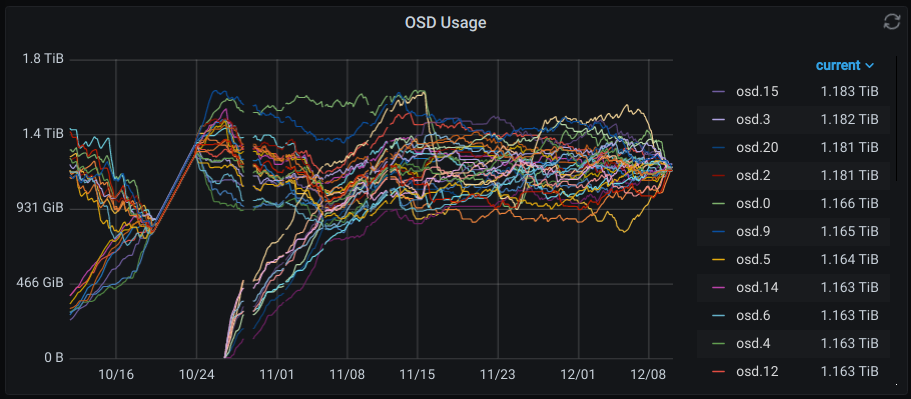
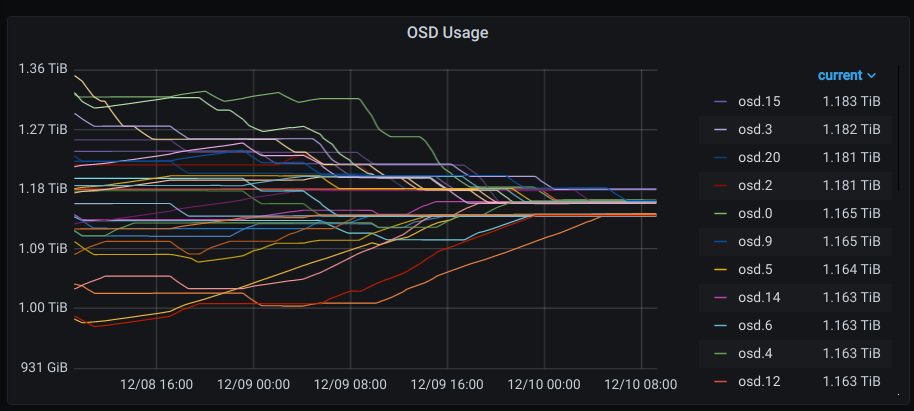
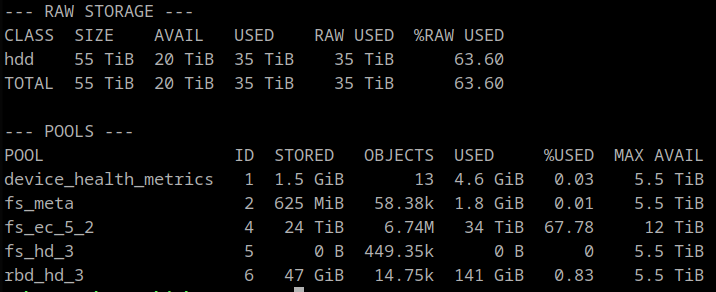
Current Total Raw Capacity: 65 TiB
The RPi's are all housed in a nine drawer cabinet with rear exhaust fans. Each drawer has an independent 5V 10A power supply. There is a 48-port network switch in the rear of the cabinet to provide the necessary network fabric.
The HDDs are double-stacked five wide to fit 10 HDDs in each drawer along with five RPi 4's. A 2" x 7" x 1/8" aluminum bar is sandwiched between the drives for heat dissipation. Each drawer has a custom 5-port USB power fanout board to power the RPi's. The RPi's have the USB PMIC bypassed with a jumper wire to power the HDDs since the 1.2A current limit is insufficient to spin up both drives.
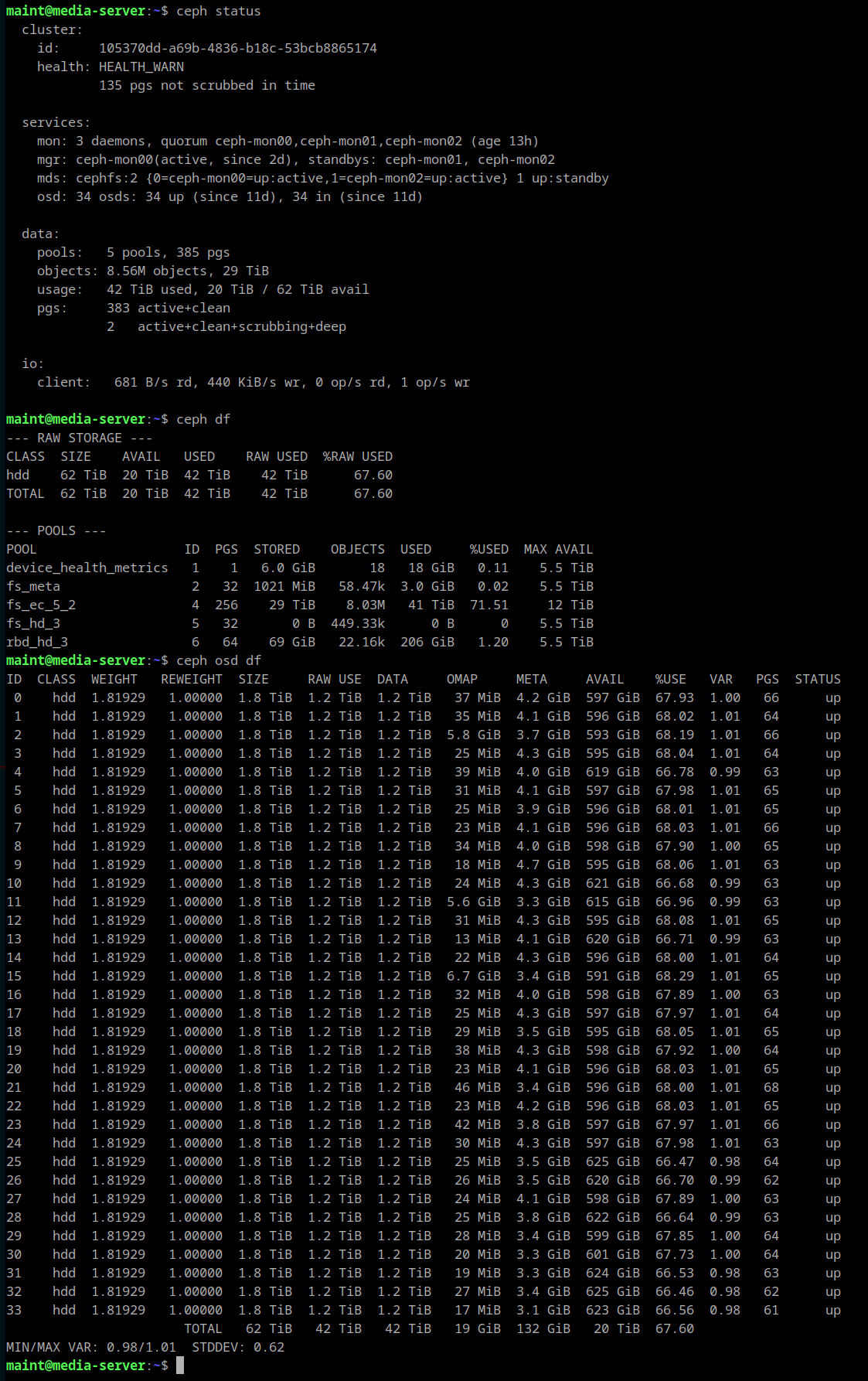
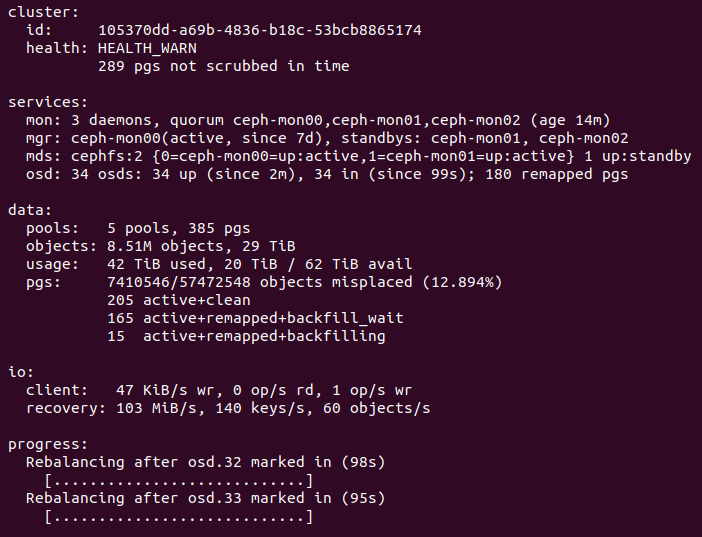

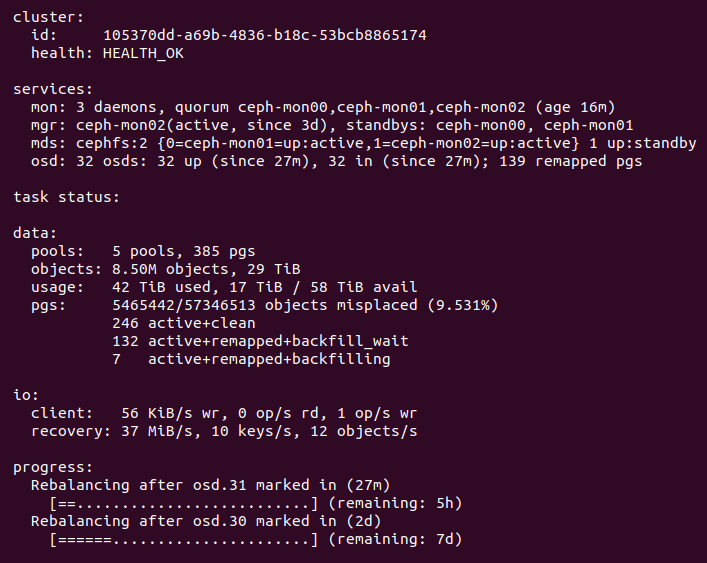
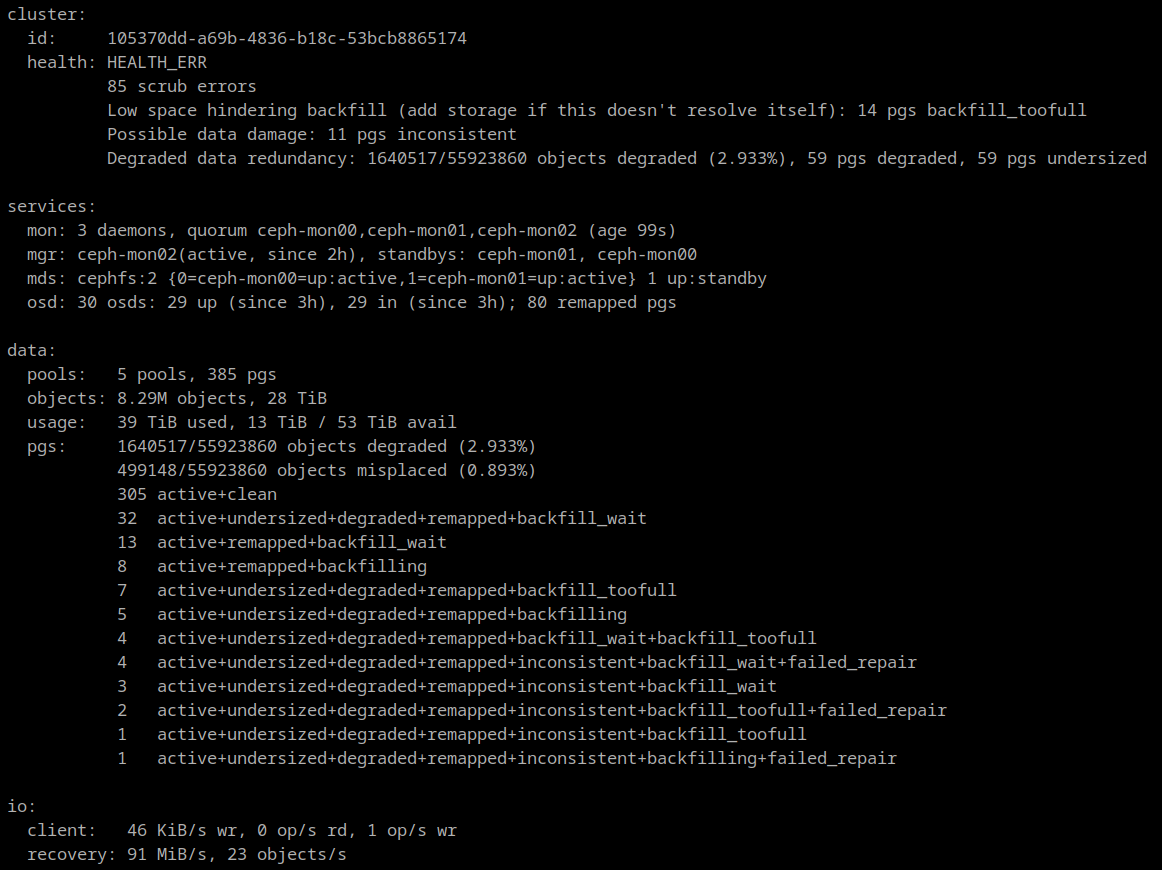
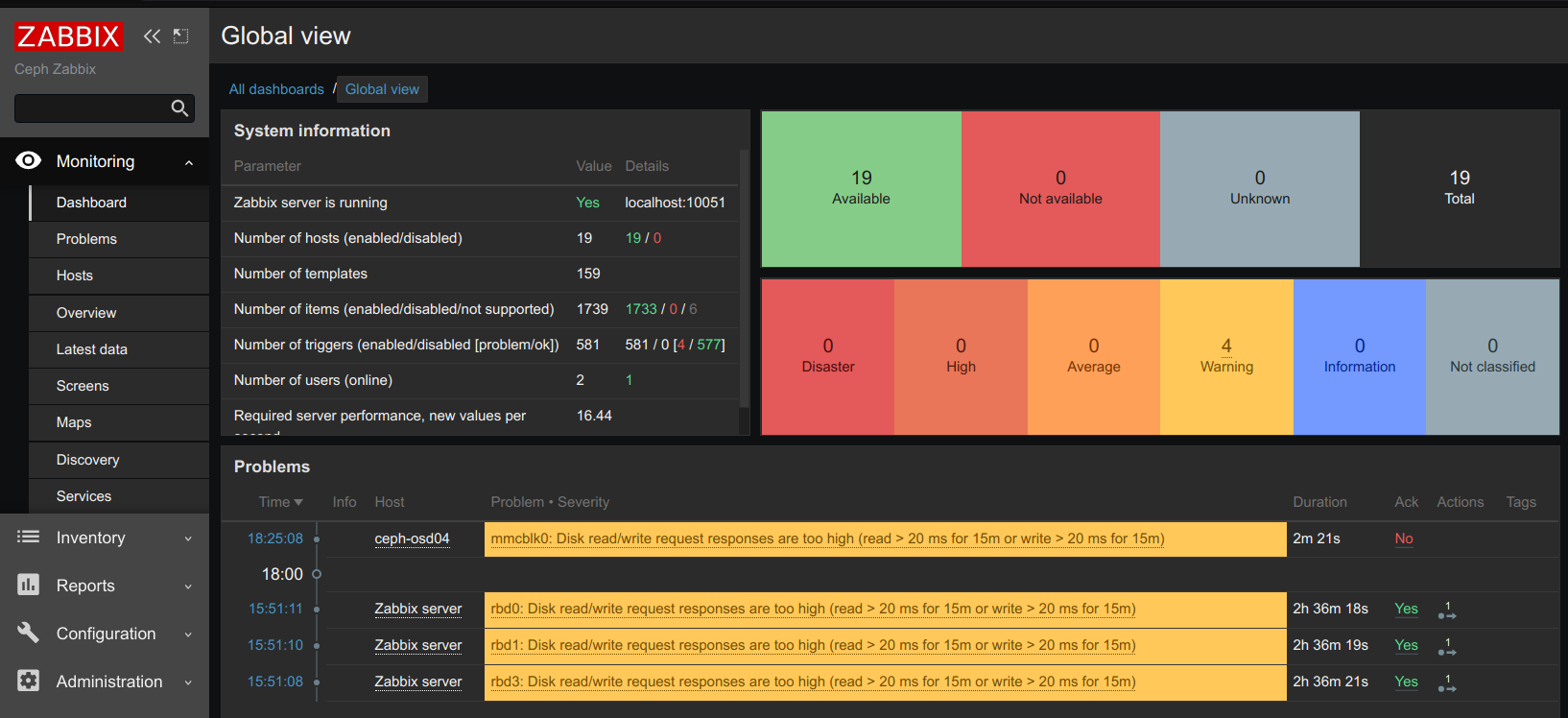
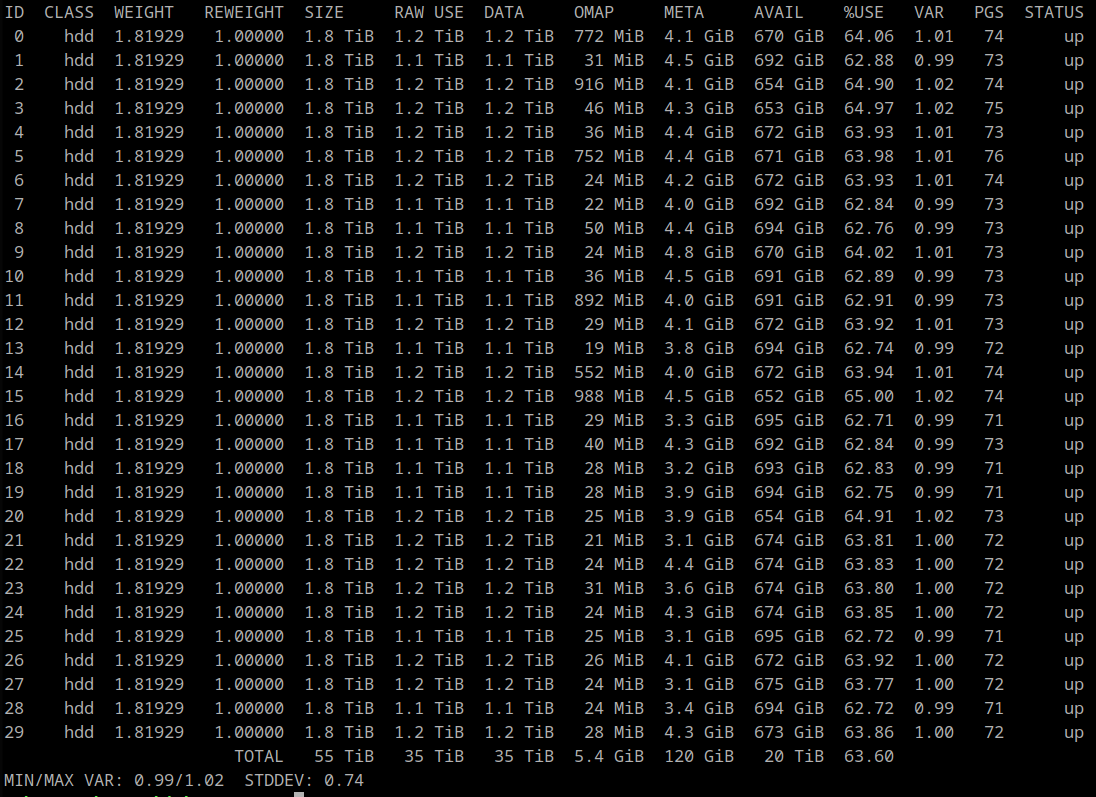
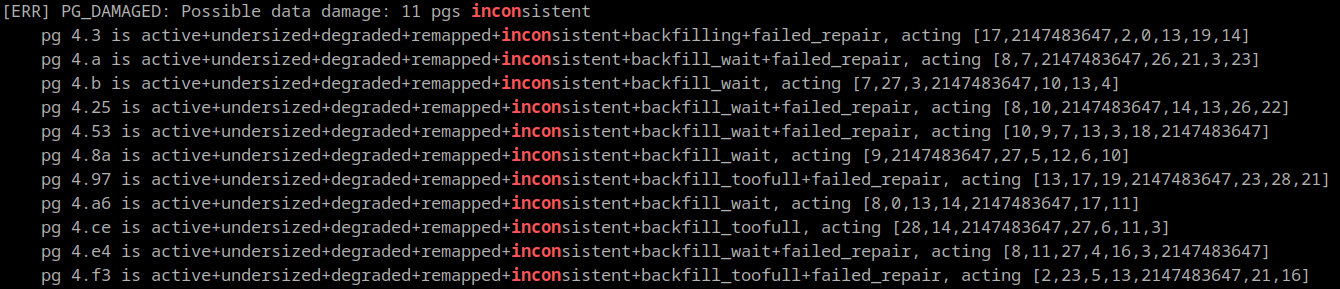 The inconsistent PGs all have a single OSD in common: 2147483647 (formerly identified as 25)
The inconsistent PGs all have a single OSD in common: 2147483647 (formerly identified as 25)











 Clara Hobbs
Clara Hobbs
 matthewkleinmann
matthewkleinmann
I'm planning something similar, hopefully in the near future. Presently I'm waiting for the ComputeBlade aka BladePi project to start selling, then setting up a cluster starting with at least 6 nodes; I'm wondering if you have any advice for someone who is relatively new to Ceph? I'm thinking of tinkering with Ansible or similar to do provisioning for my project.
The short term plan would be 3 mon nodes, plus 3 OSDs. Long term, adding upwards of 14-34 more OSDs (total of either 17 or 37); my focus is on IO performance more than throughput. The ComputeBlade OSDs would have M.2 NVMe drives, and I'm thinking of picking up 1 or 2TB models; this is to host OS disk storage for virtual machines in my homelab.
What are you using this cluster for? what is your IO throughput? any other comments are welcome.