 mick
mickWhy tyhac
Testing for COVID-19 at the start of the pandemic was difficult, there weren't enough test kits to go around and the kits themselves were still developing as far as reliability. Doctors have been diagnosing various diseases by listening to patients cough and breathe for decades. Researchers have conducted studies on developing machine learning models to predict if a patient has bronchitis, can we apply the same approach to COVID-19?
Yes, the answer is yes and MIT plus others have already done it and aim to provide a mobile app for testing. Pretty awesome!
One of the key pieces of information from the MIT study is that they were able to identify people who were asymptomatic of the virus using their trained model and as it turns out the cough was the key.
Now, MIT beat us this time but as MIT have already pointed out, asymptomatic people probably aren't rushing in to get tested and if MIT release an app it will still require users to download and use the app.
Tyhac aims to address these problems by providing a passive listening device that detects coughs and then runs deep learning inference on the sample to determine if it's COVID-19 positive or negative. By installing tyhac in common places such as offices, elevators and waiting rooms we can help to better protect our community by responding to detected events. Tyhac can also reduce the need for single use test kits by providing clinicians a way to test patients in real-time, providing simple to use non invasive testing.
By recording events and results tyhac helps us to better understand how the community responds during flu season. If tyhac is used in the workplace, we can manage healthy habits campaigns to ensure workers are taking care of themselves and where possible using remote working to limit the spread.
An example showing how tyhac might be deployed in waiting rooms to monitor the environment and how tyhac may be used as a tool for clinicians for patient testing and/or sampling:

How does it work?
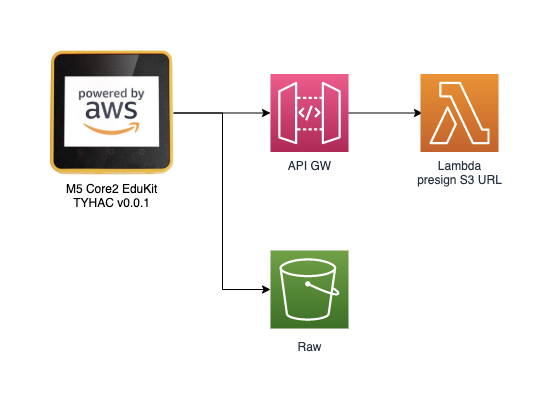
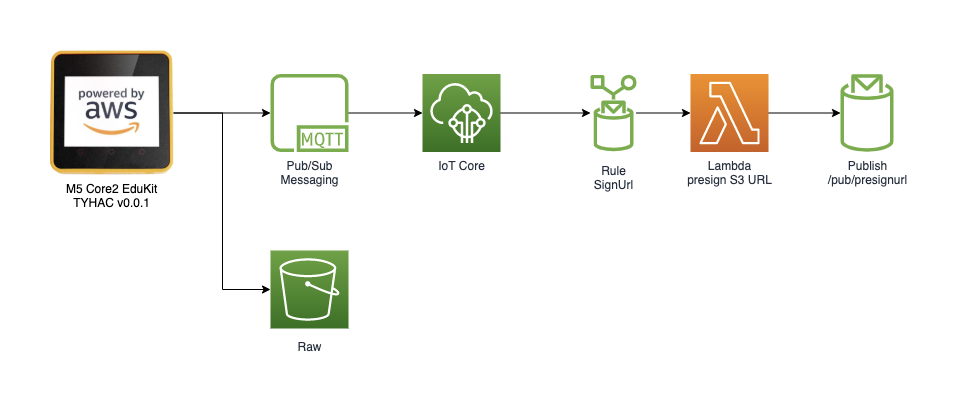
The solution itself is quite simple thanks to the M5 Core2 stack and AWS, this makes everything pretty straight forward. I've prepared a short video that will run through the high-level design of the device and AWS configuration:
Now that we have a better understanding of the stack we can talk about some of the key features and then move onto a demo. The device has been designed to operate in two modes:
Passive
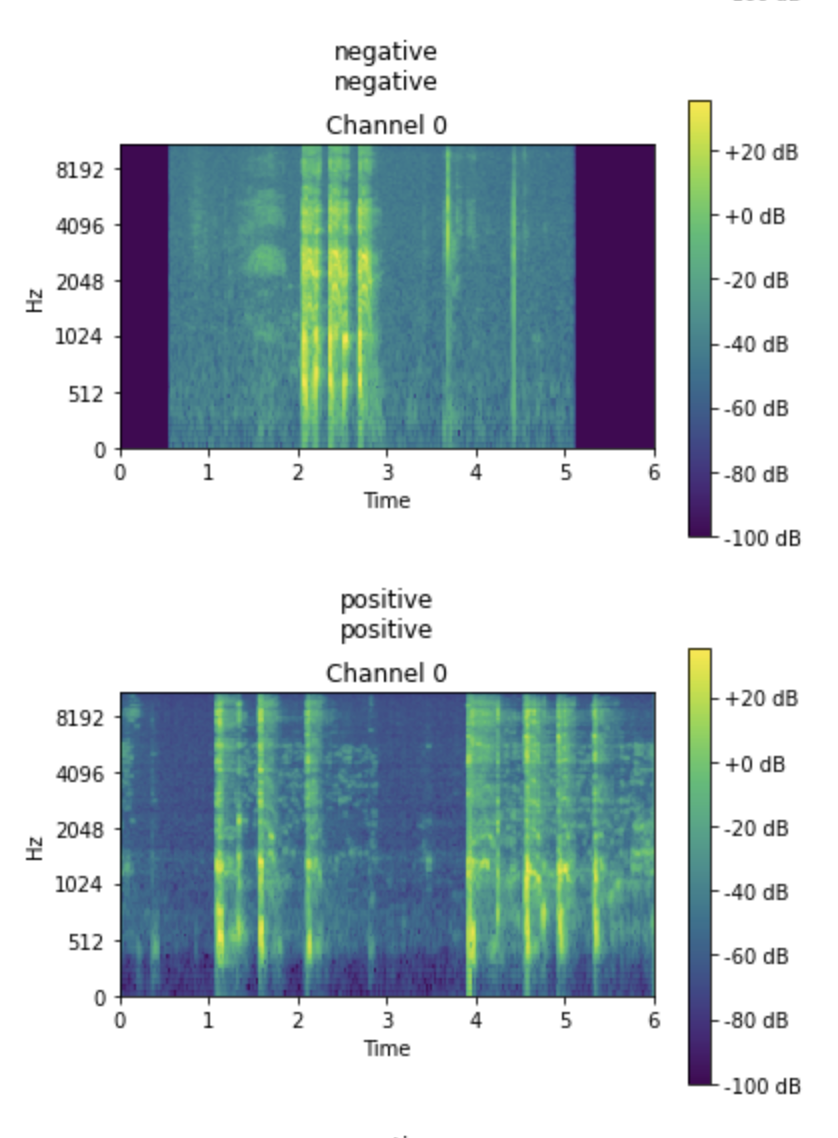
This mode has been developed for the device to be installed in a workplace, elevator, waiting room, office cubicle, home etc. The LM393 Mic Sensor has a threshold for audible nosies, once it passes that threshold the SPM1423 internal I2S microphone will begin recording a 10 second audio sample.

Clinician (Field Unit)
This mode has been designed for medical professionals, in this mode the device does not use the LM393 and is technically not required. The device can be used on battery (included with device) if preferred e.g. mobile.

The user is presented with a menu showing two options:
Submit
This button is intended for medical professionals to submit positive samples, I have included this so that we receive labelled samples to continue to train the model and improve the predictions.
Test
This button is used to diagnose a patient, once the button is pushed it will record 10 seconds of audio using the internal SPM1423 I2S microphone.
Upload
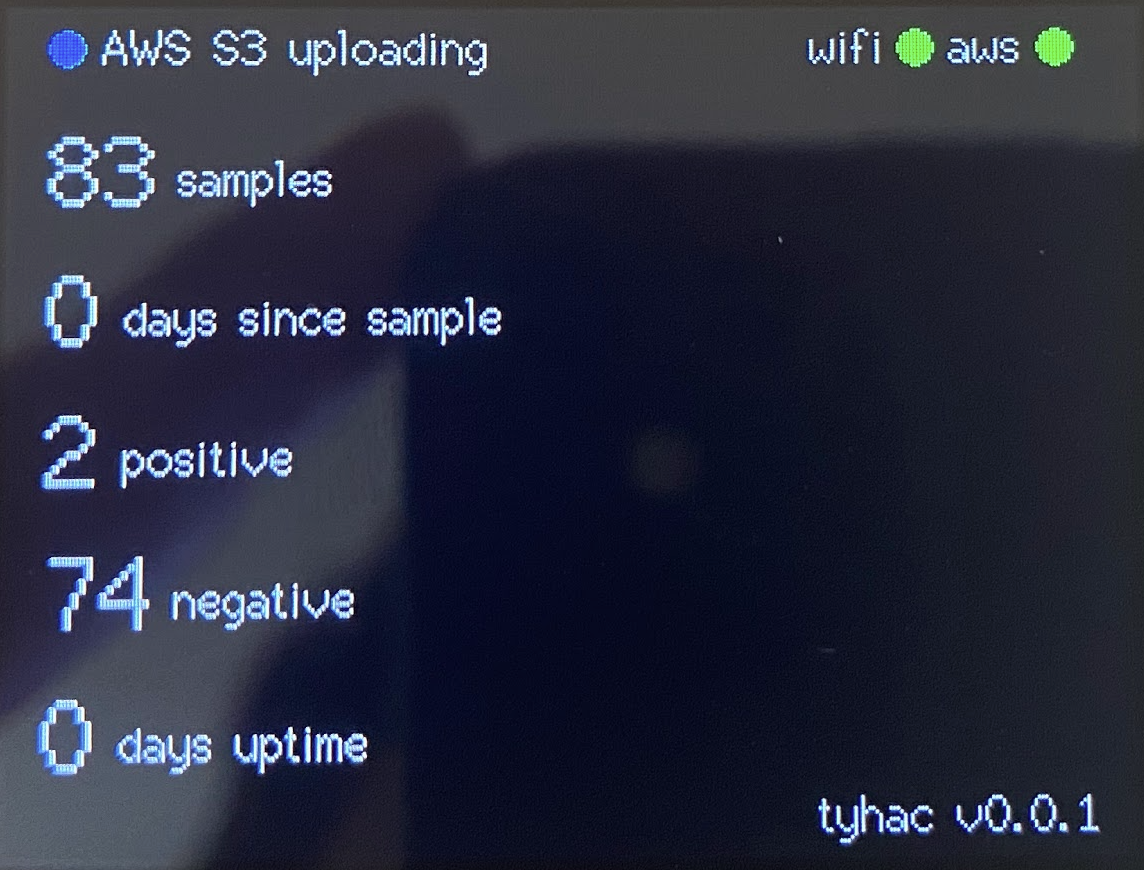
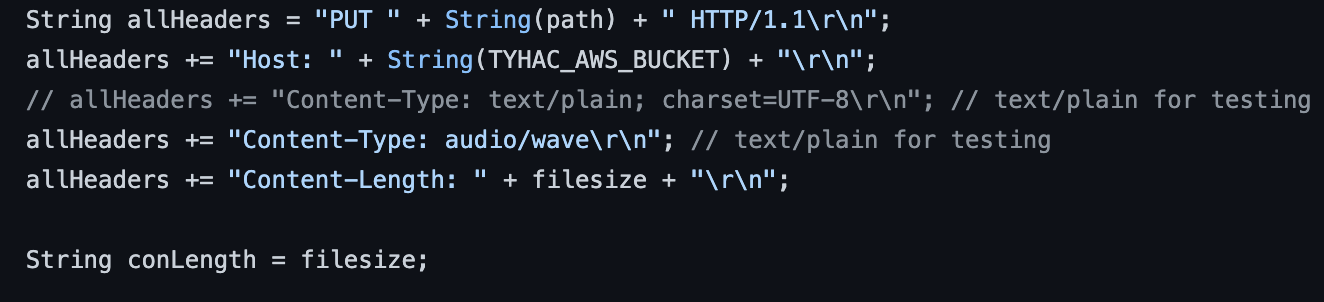
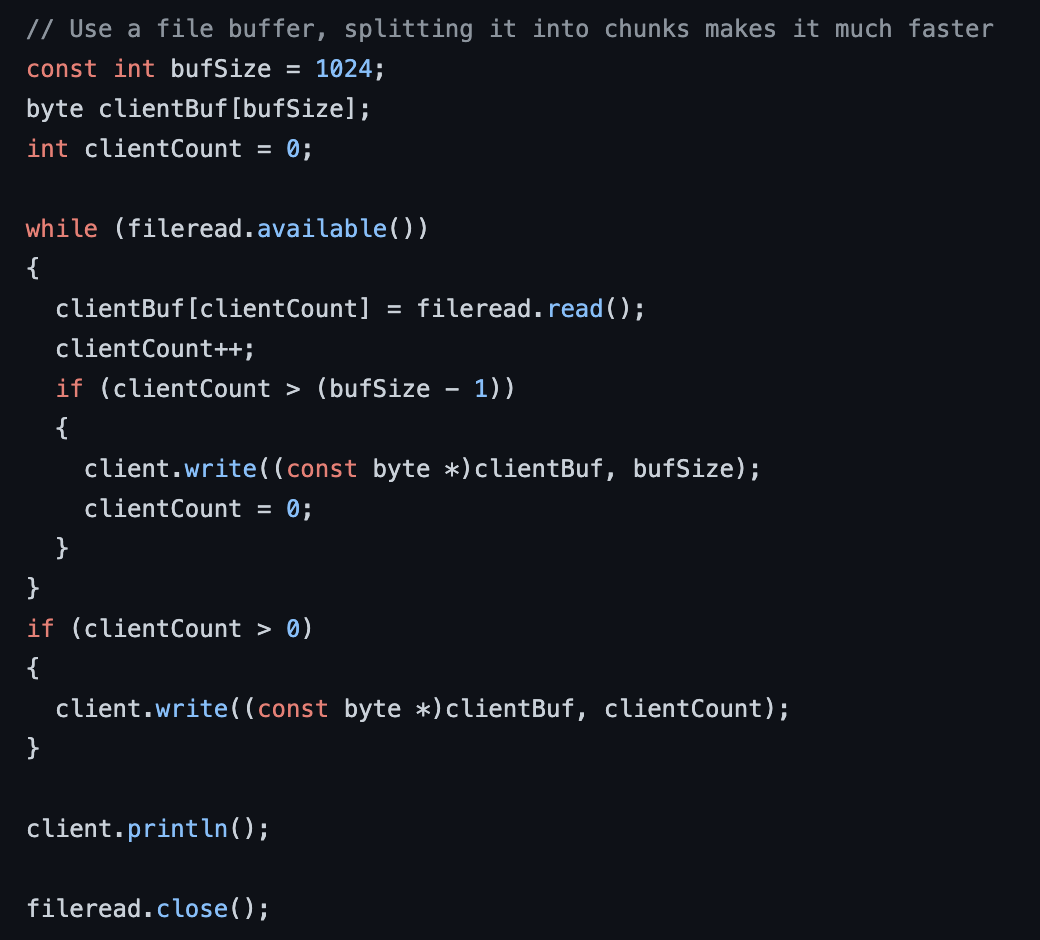
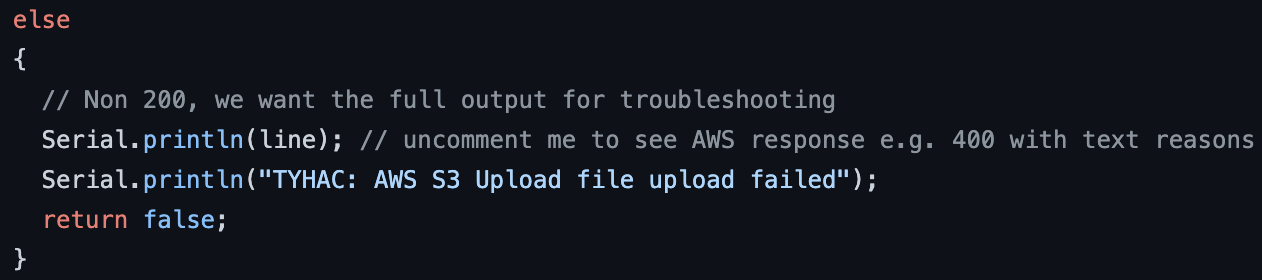
Both modes record the audio sample as a WAV file and is written to the Sdcard on the device. The device will then publish to the S3 Pre-signed URL MQTT topic to request a secure url to upload the WAV file. Once received the device will begin uploading via secure HTTPS.
Validation
Once the file has been uploaded to AWS S3 a bucket trigger event will invoke the staging Lambda function. The staging process runs a series of checks on the sample:
- Is the sample a valid WAV file?
- Is the sample a cough?
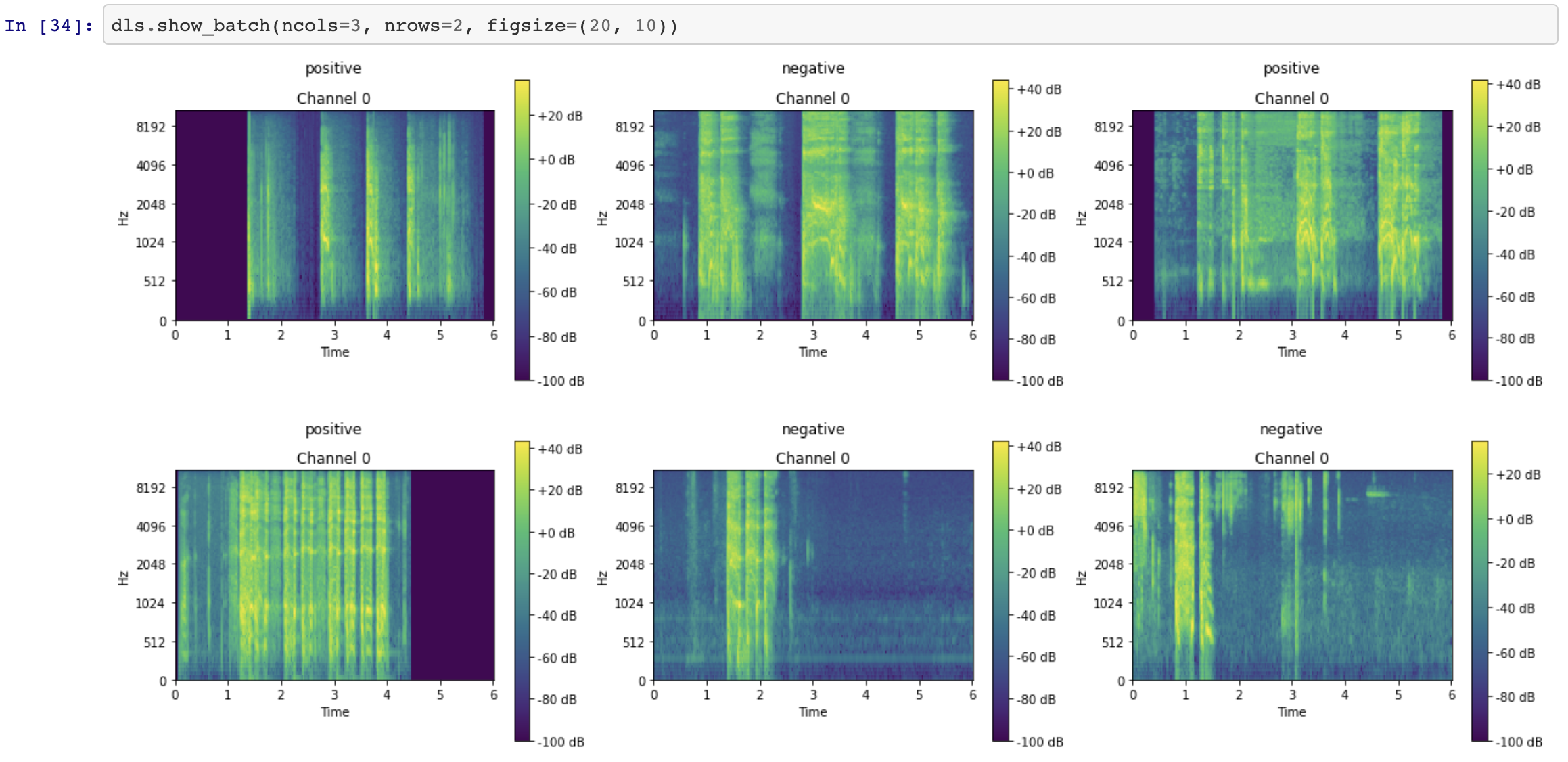
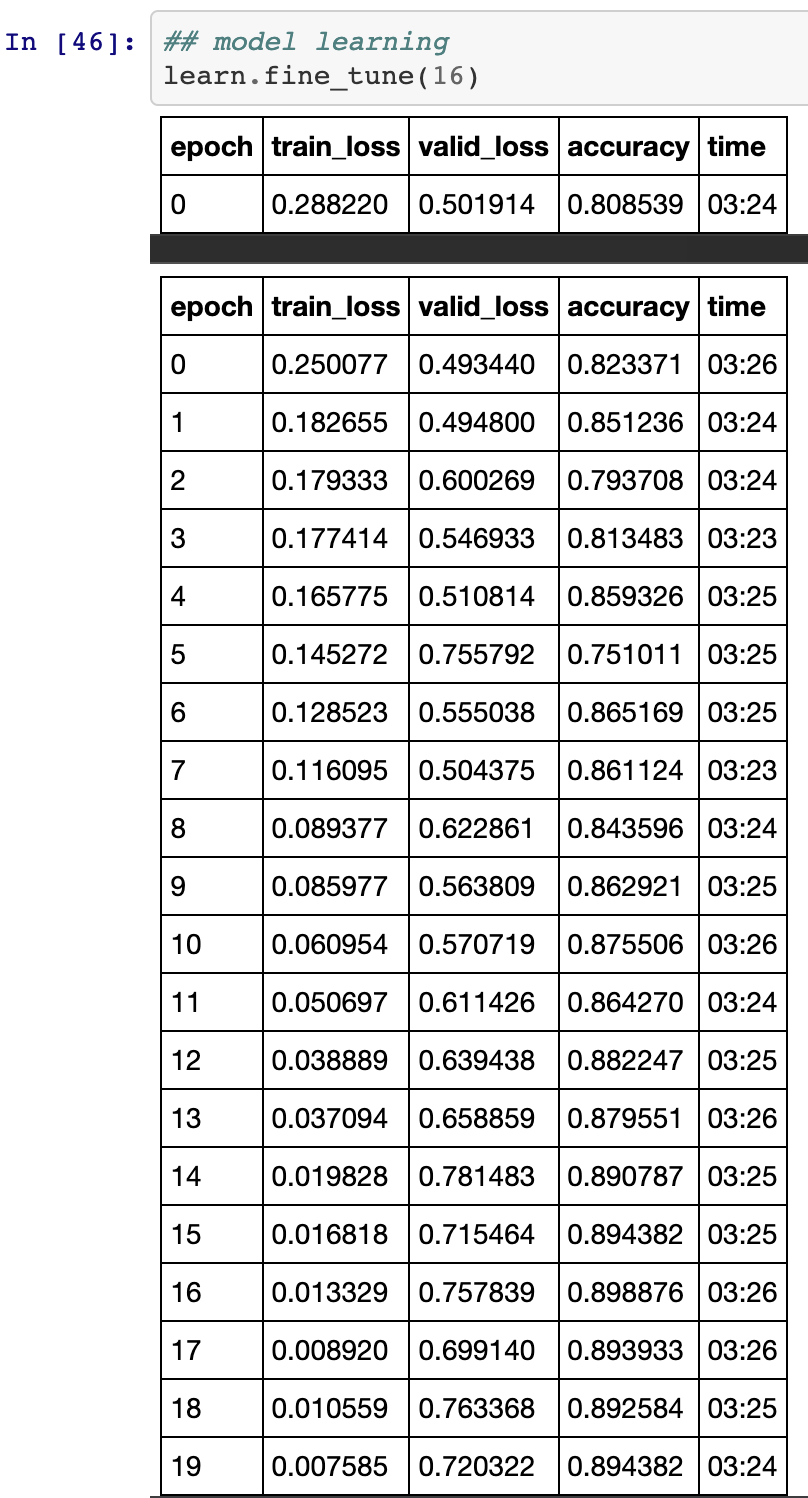
- Augment the file
- Archive the file and copy to the...












 Sumit
Sumit
 Capt. Flatus O'Flaherty ☠
Capt. Flatus O'Flaherty ☠
 Steven Hickson
Steven Hickson
 Tom
Tom