 Yann Guidon / YGDES
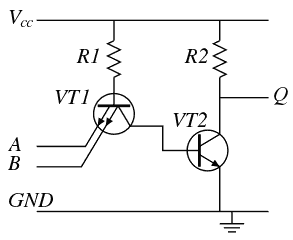
Yann Guidon / YGDESThanks to @Morning.Starfor drawing the project's avatar :-) Of course the current source is missing, but it's on purpose. It's a reminder that a nice looking idea can be badly engineered and you have to try it to see how or why it doesn't work. This picture is the simplest expression of this principle :-)
See also #POSEVEN (ex "NPM - New Programming Model")
I must emphasize: this is not a "general introduction" to CPU or their design but a general analysis of how I design MY processors:
- The #F-CPU
- The YASEP : #Discrete YASEP - #YASEP Yet Another Small Embedded Processor - #microYasep . . .
- The YGREC #YGREC16 - YG's 16bits Relay Electric Computer - #YGREC-РЭС15-bis - #YGREC-Si - #YGREC8 - #YGREC-ECL - #YGRECmos
- The 2nd generation YGREC: #YGREC32
Note: these are "general purpose" cores, not DSP or special-purpose processors, so other "hints" and "principles" would apply in special cases.
I list these "principles" because :
- I encourage people to follow, or at least examine and comment, these advices, heuristics, tricks. I have learned from many people and their designs, and here I contribute back.
- They help people understand why I chose to do something in a certain way and not another in some of my designs. I have developed my own "style" and I think my designs are distinctive (if not the best because they are mine, hahaha.)
- It's a good "cookbook" from which to pull some tricks, examine them and maybe enhance them. It's not a Bible that is fixed for ever. Of course this also means that it can't be exhaustive. I document and explain how and why this, and not that, along the way...
- I started to scratch the surface with #AMBAP: A Modest Bitslice Architecture Proposal but it was lacking some depth and background. AMBAP is an evolution of all those basic principles.
- The 80s-era "canonical RISC" structure needs a long-awaited refresh !
- This can form the foundations for lectures, lessons, all kinds of workshops and generally educational activities.
Hope you like it :-)
Logs:
1. Use binary, 2s complement numbers
2. Use registers.
3. Use bytes and powers-of-two
4. Your registers must be able to hold a whole pointer.
5. Use byte-granularity for pointers.
6. Partial register writes are tricky.
7. PC should belong to the register set
8. CALL is just a MOV with swap
9. Status registers...
10. Harvard vs Von Neuman
11. Instruction width
12. Reserved opcode values
13. Register #0 = 0
14. Visible states and atomicity
15. Program Position Independence
16. Program re-entrancy
17. Interrupt vector table
18. Start execution at address 0
19. Reset values
20. Memory granularity
21. Conditional execution and instructions
22. Sources of conditions
23. Get your operands as fast as possible.
24. Microcode is evil.
25. Clocking
26. Input-Output architecture
27. Tagged registers
28. Endians
29. Register windows
30. Interrupt speed
31. Delay slots
32. Split vs unified register set (draft).
33. Code density (draft)
34. Reset values (bis)
35. ILP - Instruction Level Parallelism (draft)
36. Stack processors (draft)
37. VLIW - Very Long Instruction Word architectures (draft)
38. TTA - Transfer-Triggered Architectures
39. Divide (your code) and conquer
40. How to design a (better) ALU
41. I have a DWIM...
42. Coroutines
43. More condition codes
44. How to name opcodes ? (draft)
45. Be ready to change your opcode map a lot, until you can't
46. The perfect ISA doesn't exist.
47. Learn and know when to stop
48. The 4 spaces
49. NAND or NOR ? A taxonomy of topologies
50. Choosing boolean instructions
51. Privileged instructions
52. Tagged registers: type
53. Carry and borrow
54. Use two separate stacks for data and control flow
55. Let the hardware do what it does best.
.
(some drafts are still pending completion)


 Dylan Brophy
Dylan Brophy

https://player.vimeo.com/video/450406346 Nice little conference about the Larrabee, KNI, AVX512 saga