 Yann Guidon / YGDES
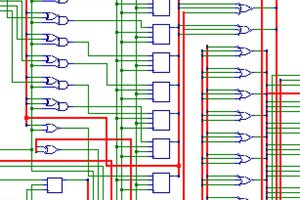
Yann Guidon / YGDES This project contains a set of tools that process VHDL files mapped to FPGA/ASIC/arbitrary logic gates, so it is useful as a step between the synthesis of a circuit and the place&route operation. This is an exploratory toolset, constrained to a specific step of the logic design workflow, as it does not modify or transform the source netlist but gives insight into its often invisible structure, and guides the designer while writing it, in an interactive, iterative process, while focusing on specific digital units. As such, it is complementary but not a replacement of abc or yosys, which have way broader reach and features.
You can:
- Simulate the circuit (for example, if your synthesiser has mapped the gates to a given PDK but you don't have the corresponding gates definitions in VHDL)
- Perform static analysis of the netlist (spot unconnected inputs or outputs, and other common mistakes, beyond what VHDL already catches by default)
- Extract dynamic activity statistics (how often does a wire flip state, if at all, during typical operation ?)
- Verify that any internal state can be reached (thus helping with logic simplifications)
- Alter any boolean function, inject arbitrary errors, optimise and prove your BIST strategy
- Extract logic traversal depth and estimate speed/latency (roughly)
- Inspect logic cones, see what inputs and outputs affect what
- Help with replacing DFFs with transparent latches
- Ensure that the circuit is correctly initialised with the minimal amount of /RESET signals (saving routing and area)
- Detect and break unexpected logic loops or chains
Some day, it could be extended to
- Pipeline a netlist and choose the appropriate strategy (will require detailed timing information, yosys probably does this already ?)
- Customise the set of available gates to emulate or substitute arbitrary PDK/ALIs.
- Transcode/Transpile a netlist from one family/technology/ALI to another
- Which also means the ability to create custom ALIs from analysis of a design unit...
- Import/export to Liberty, EDIF, Verilog, FPGA bitstream or others ?
Note: Since the tool typically processes netlists before place&route, no wiring parasitics data are available yet so no precise timing extraction is possible and it doesn't even try. It can however help, in particular with extraction of the criticality of each path then the mapping of gates to the proper fanout.
The project started as #VHDL library for gate-level verification but the scope keeps extending and greatly surpasses the mere ProASIC3 domain. For example I also study the addition of the minimalist OSU FreePDK45. More unrelated libraries would be added in the near future, depending on applications : Skywater PDK, Chip4Makers' FlexCell and Alliance could follow. Contact me if you need something !
Logs:
1. First upload
2. Second upload
3. Rewrite
4. More features ! (one day)
5. Another method to create the wrapper
6. inside out
7. OSU FreePDK45 and derivatives
8. The new netlist scanner
9. Chasing a "unexpected feature" in GHDL
10. Polishing and more bash hacking
11. Completeness of a simple heuristic
12. Benchmarking with a HUGE LFSR
13. Benchmarking results
14. Wrapper rewrite
15. A smarter sinks list allocator
16. Strong typing snafu
17. Plot twist
18. Skipping the preflight check
19. Depthlist v2
20. Better detection of driver conflicts
21. Custom mode with arbitrary ALI
22. More async
23. Meanwhile, GHDL...
24. Update 20220528
25. ALIberty
26. Two outputs and more inputs
27. ALI definition
28. The taxonomy of Set/Reset latches
29. More inputs ? No, finer gate delays.
.
.
.
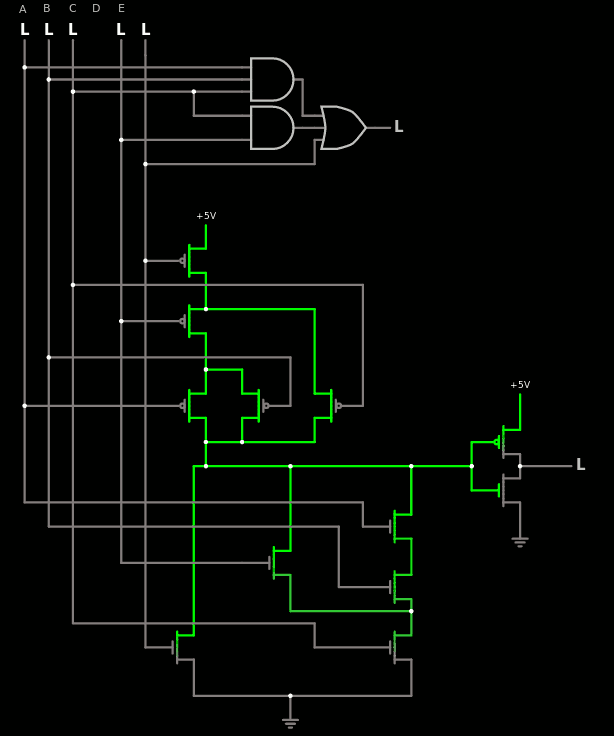
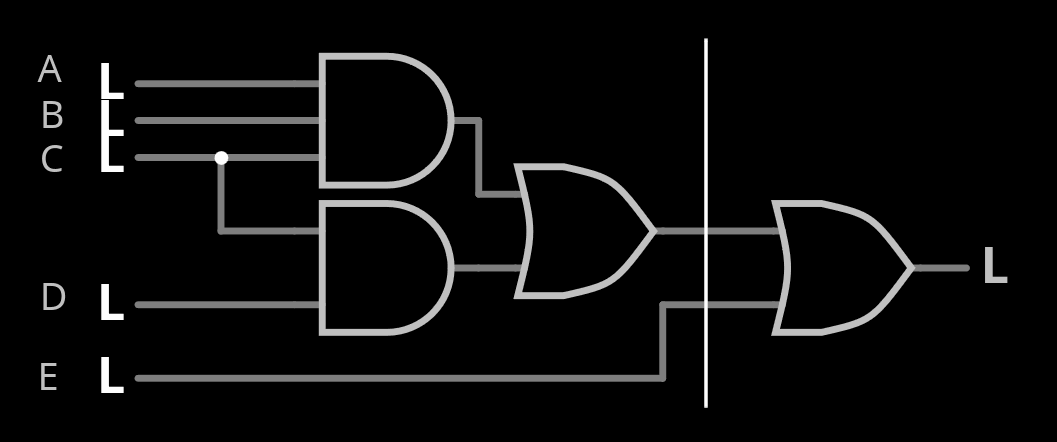
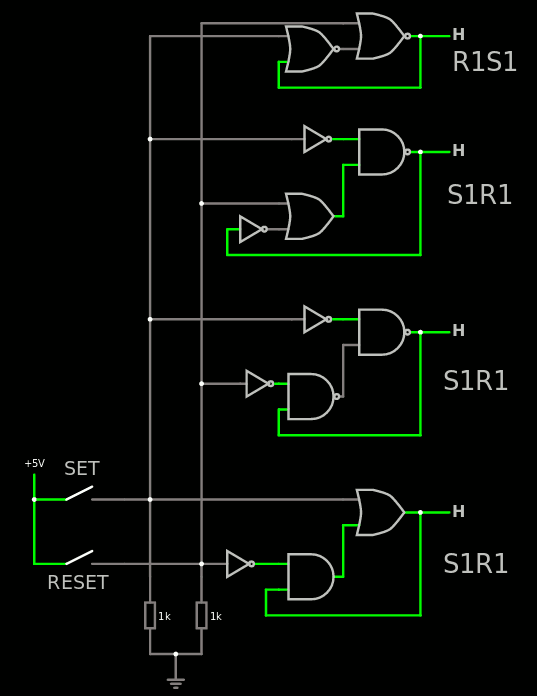
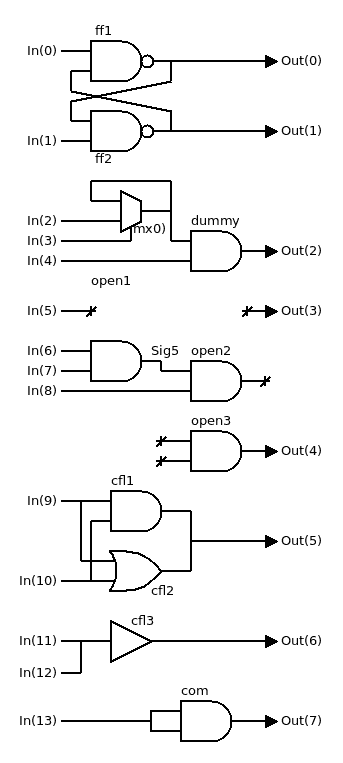







 Al Williams
Al Williams
https://pdk.libresilicon.com/ :-D