 Aleksa
AleksaI started this project sometime in 2018 and have been working on it ever since. From the very beginning, I've planned to release this project as open source, but fell prey to perhaps the most classic excuse open source has to offer: "I'll release it when I'm done". And so, the project moved forward, past various milestones of done-ness. And my fear of showing not just my work, but the (sometimes flawed, and always janky) process behind it kept me making the same excuse. In doing so, I've missed out on the input of the open-source community that I've spent so long lurking in, spent nights banging my head against problems that could have been spotted earlier, and slowed down the project as a whole.
"The best time to open source your project was when you started it, the second best time is now"
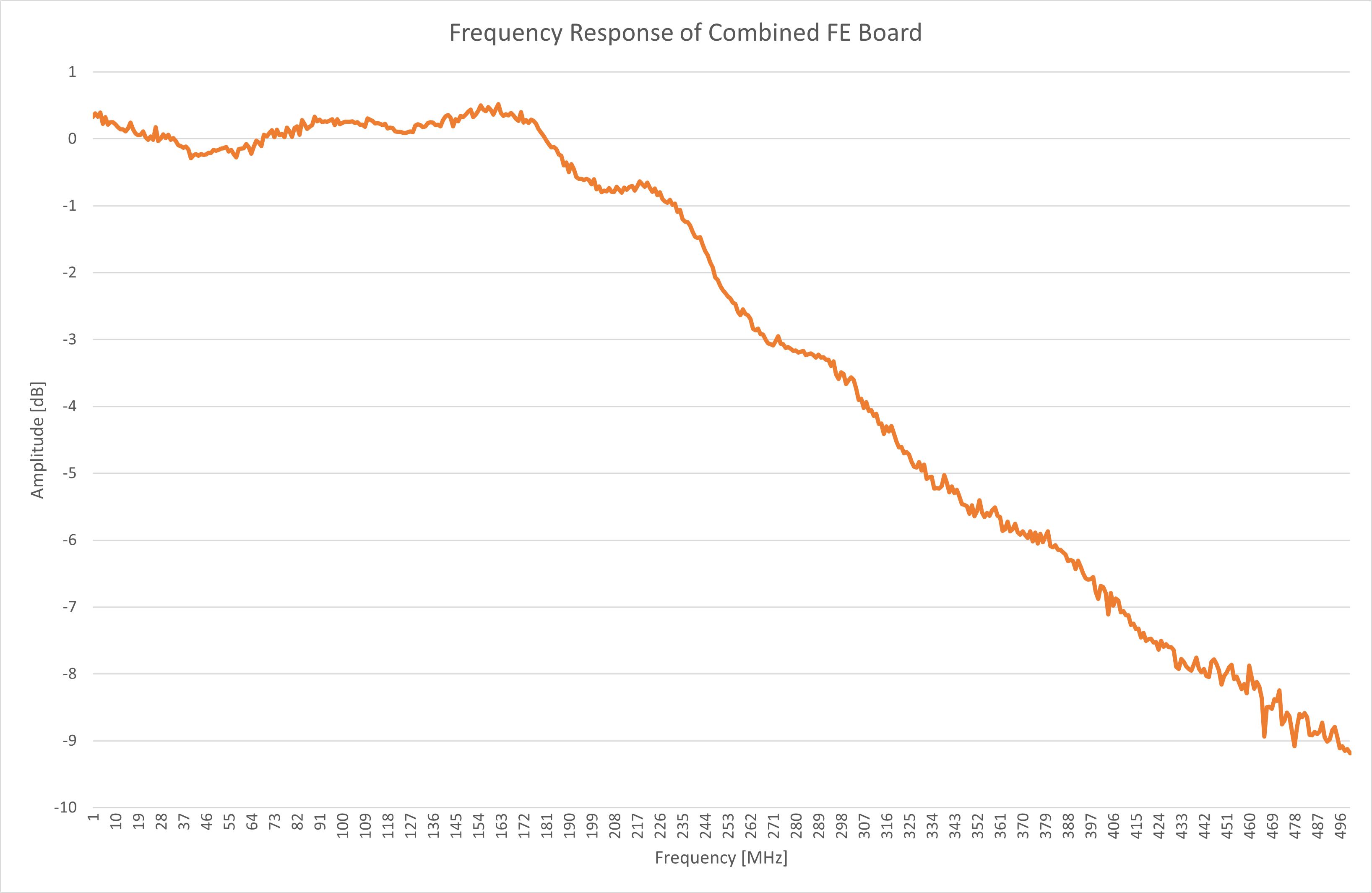
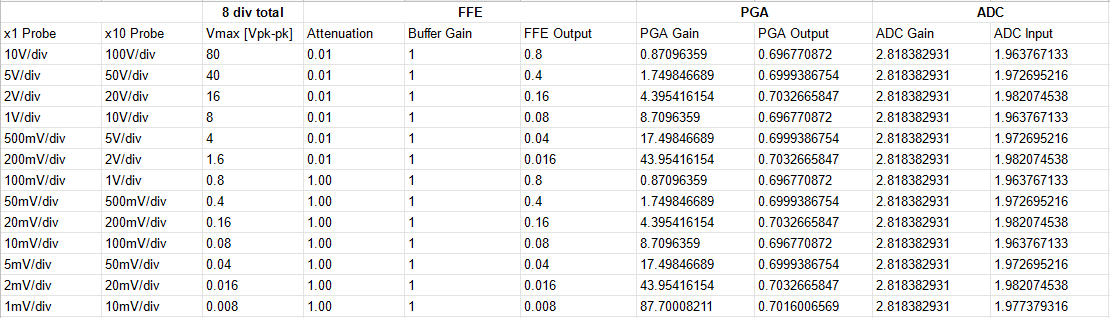
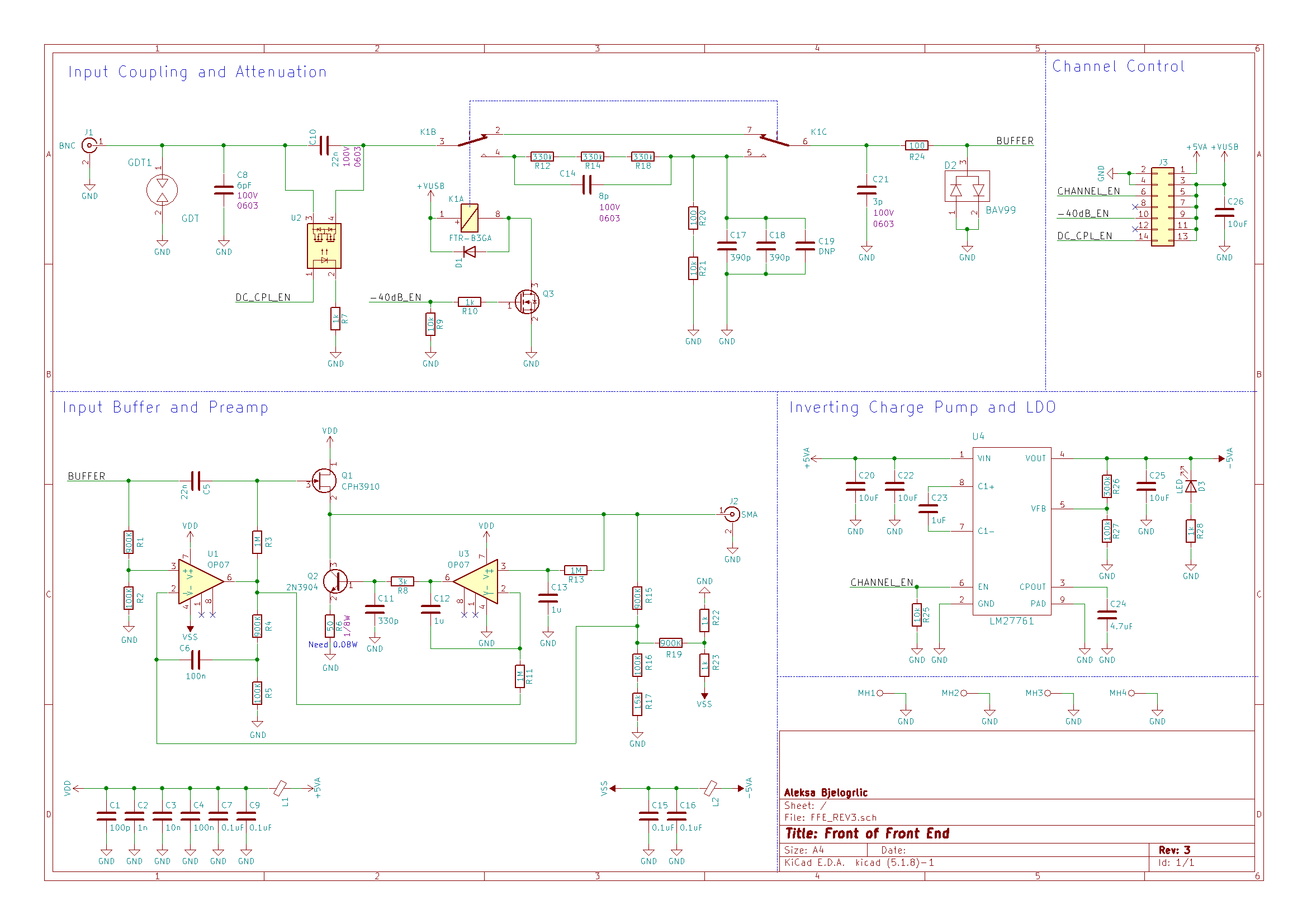
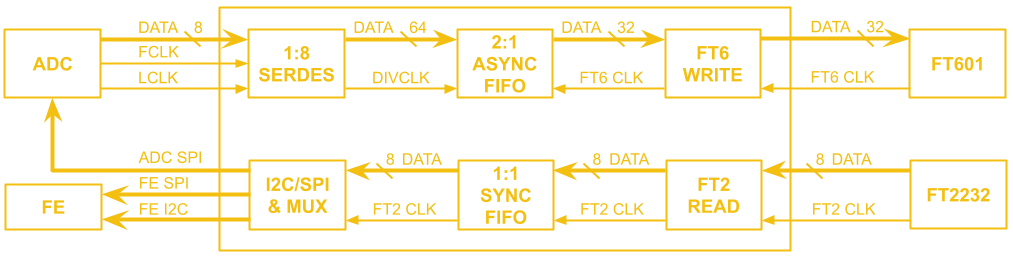
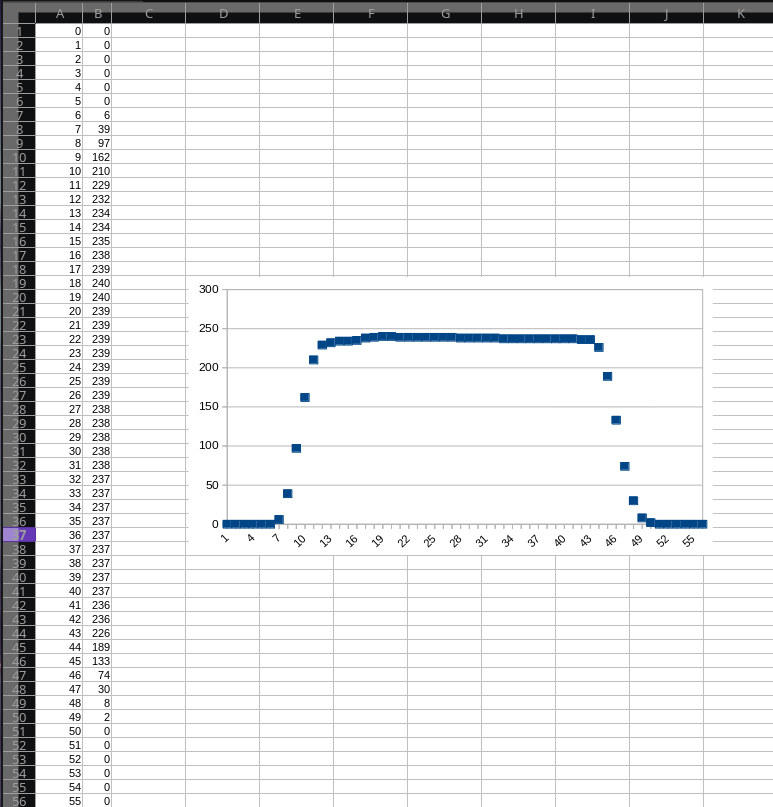
The project is now in a near-completed state and is released as open-source on GitHub under an MIT license. I will be making a series of project posts here detailing all the failures, fixes, and lessons learned in chronological order. I look back to when I was first learning about hardware through following open source projects and although I could learn a bit from finished layouts and schematics, the most I've learned is from blog posts and project logs that describe the problems faced and how they were solved. I wish to do the same for those just starting out in this amazing field, and hopefully also release an excellent oscilloscope for them to use in their electronics journey! If you're interested, sign up at Crowd Supply to be notified when the campaign starts!

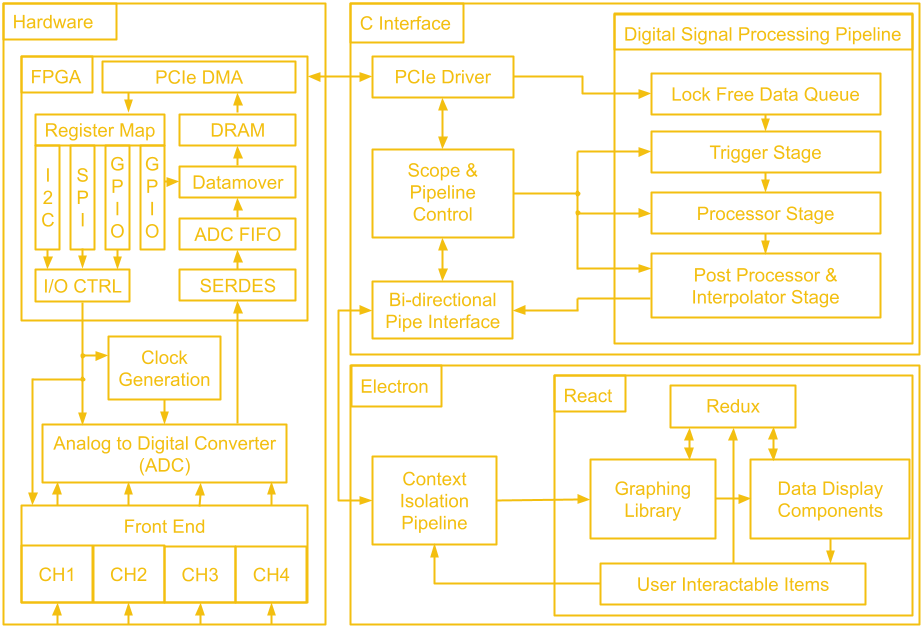
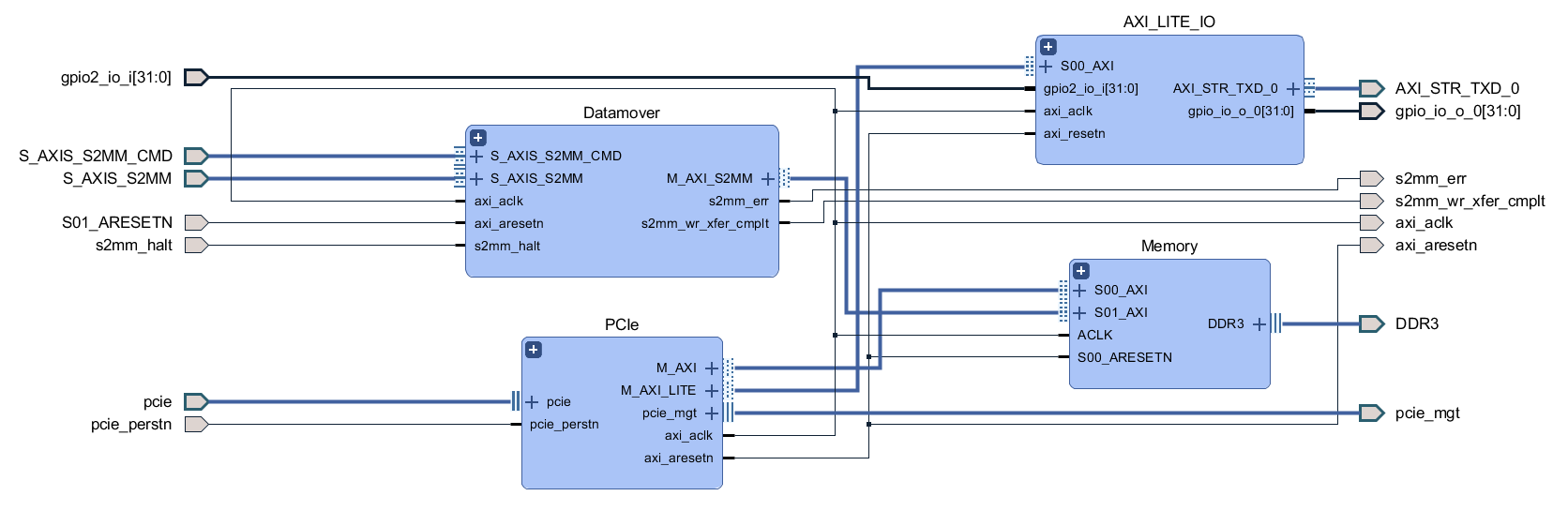

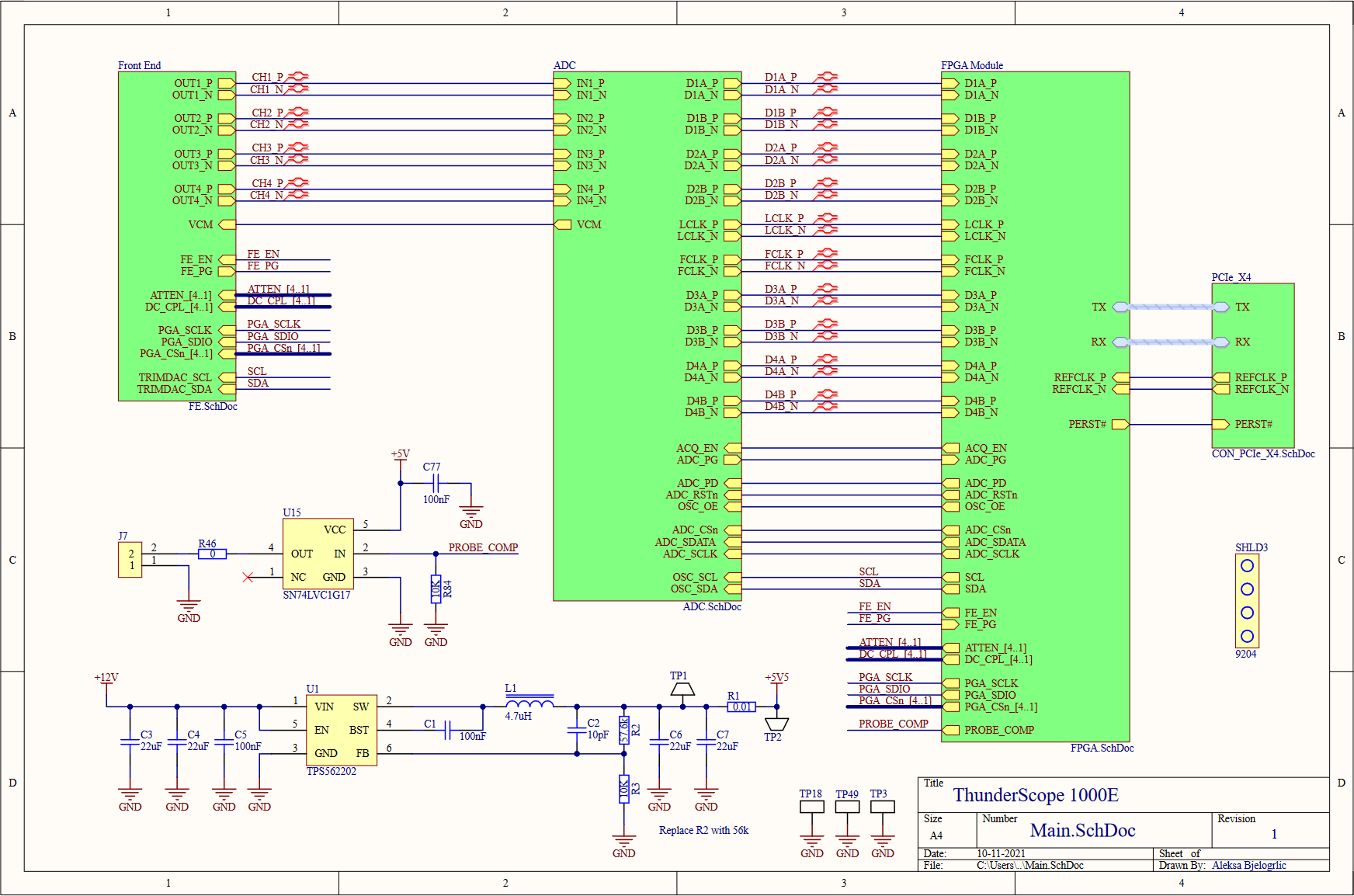
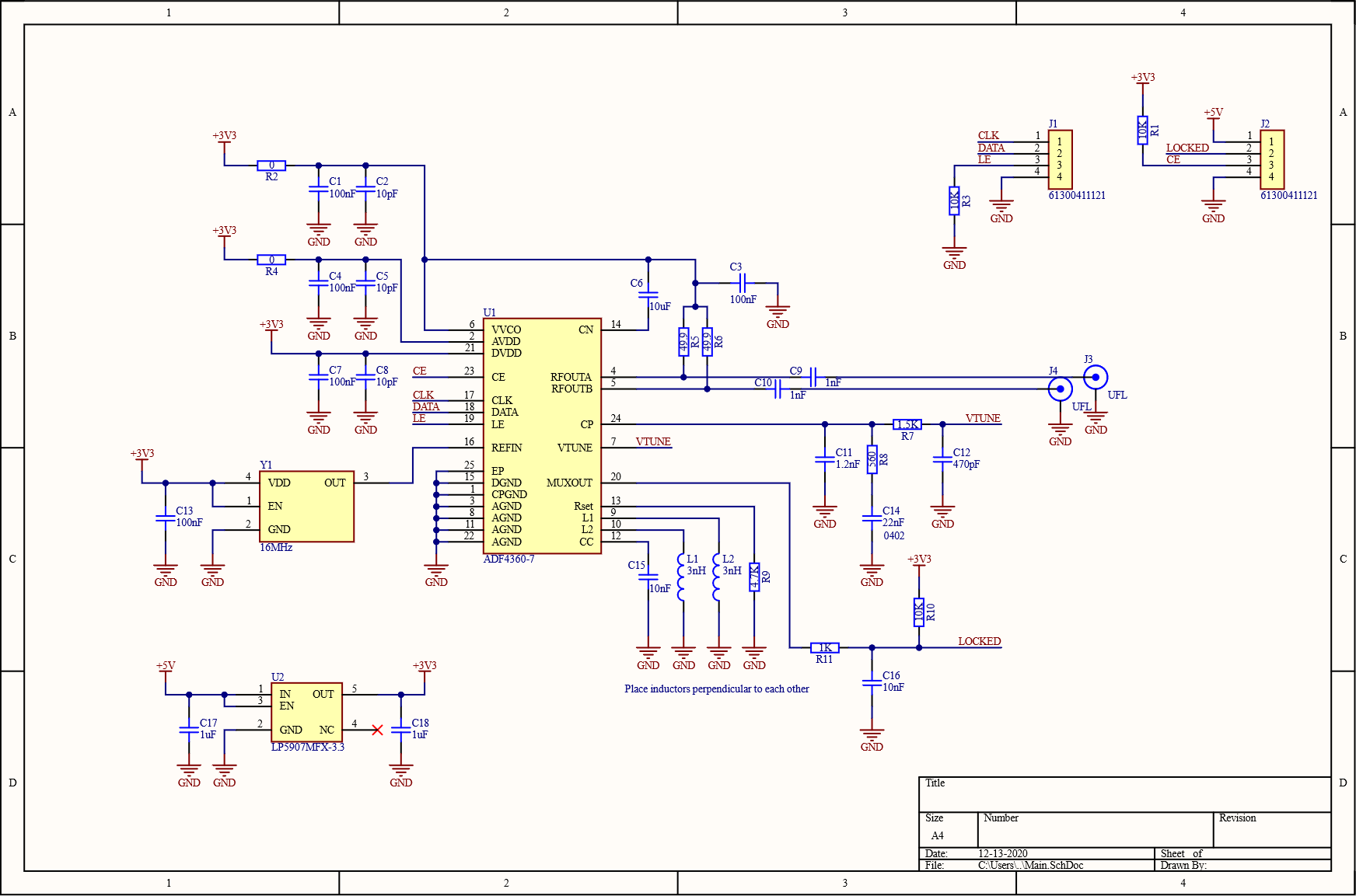


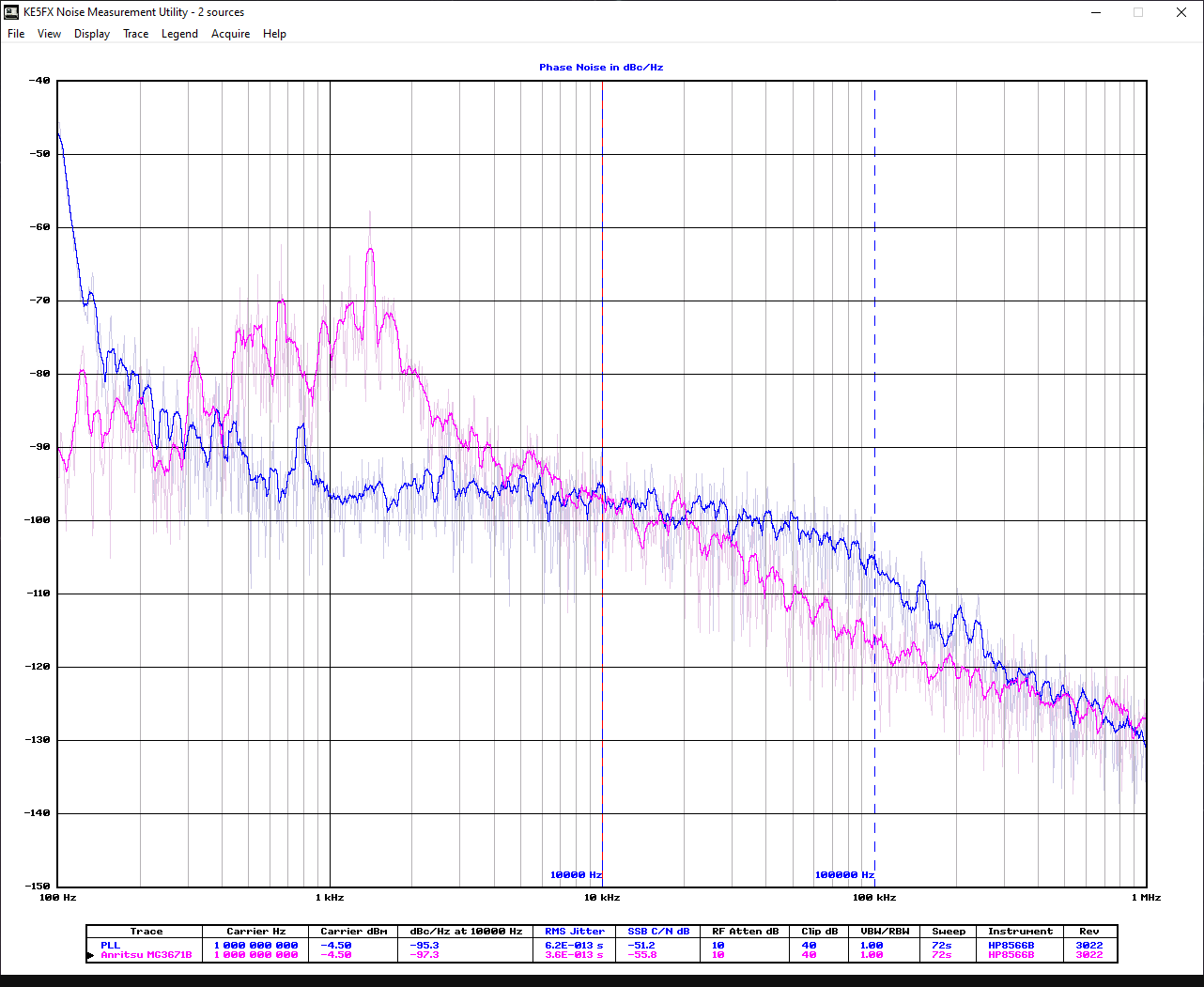

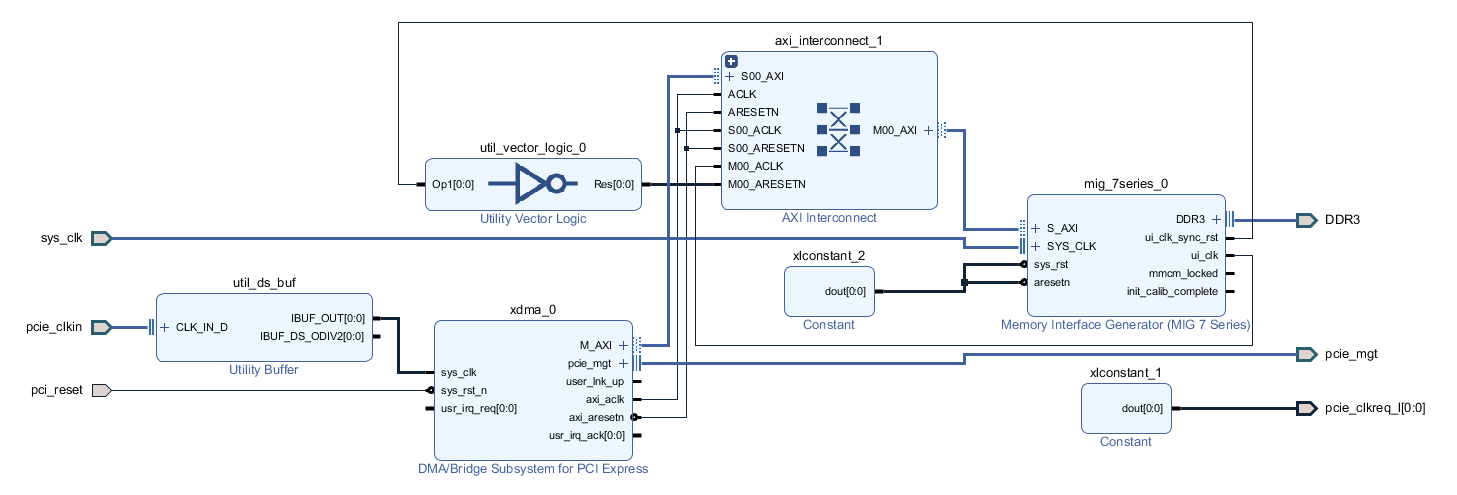

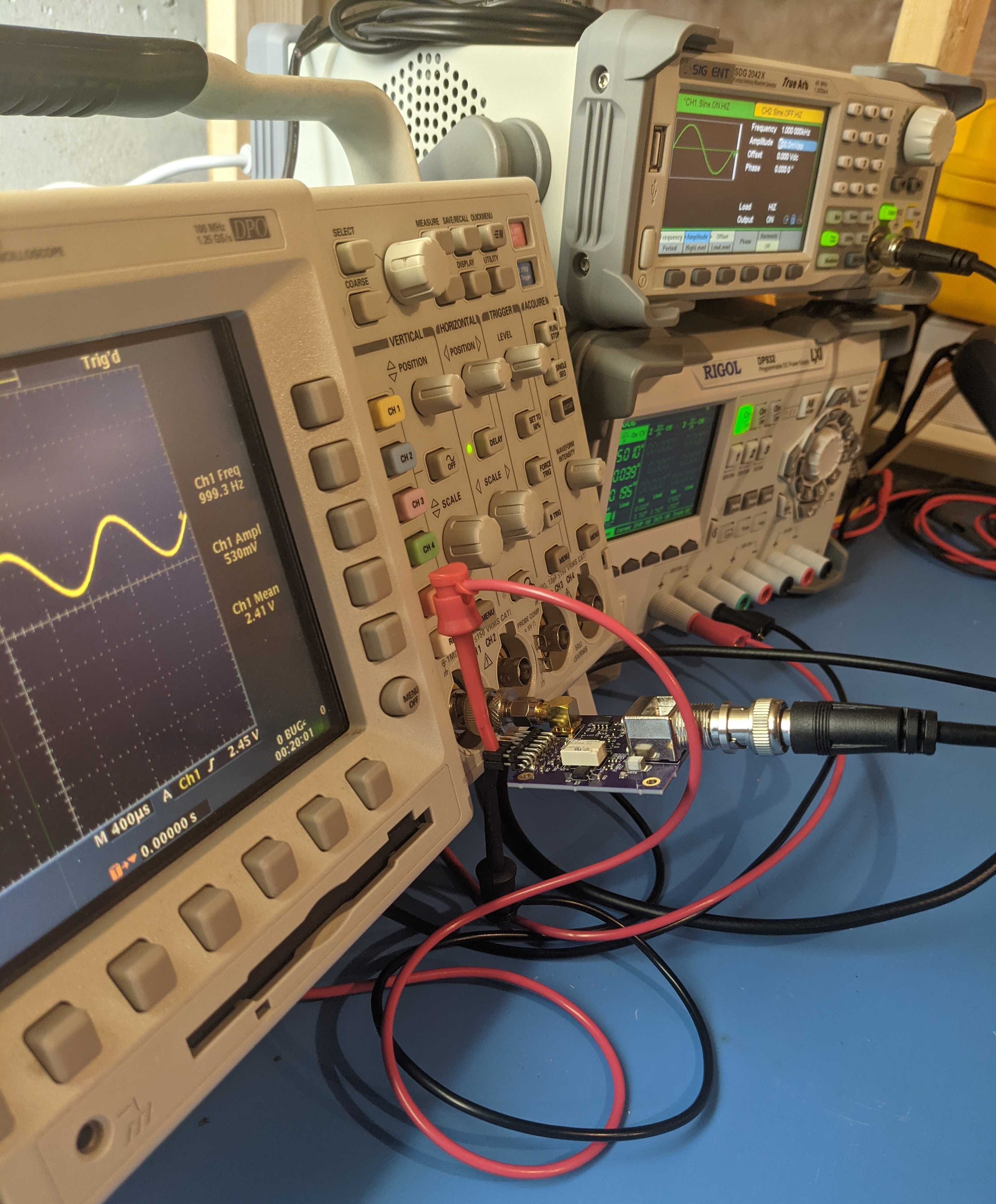

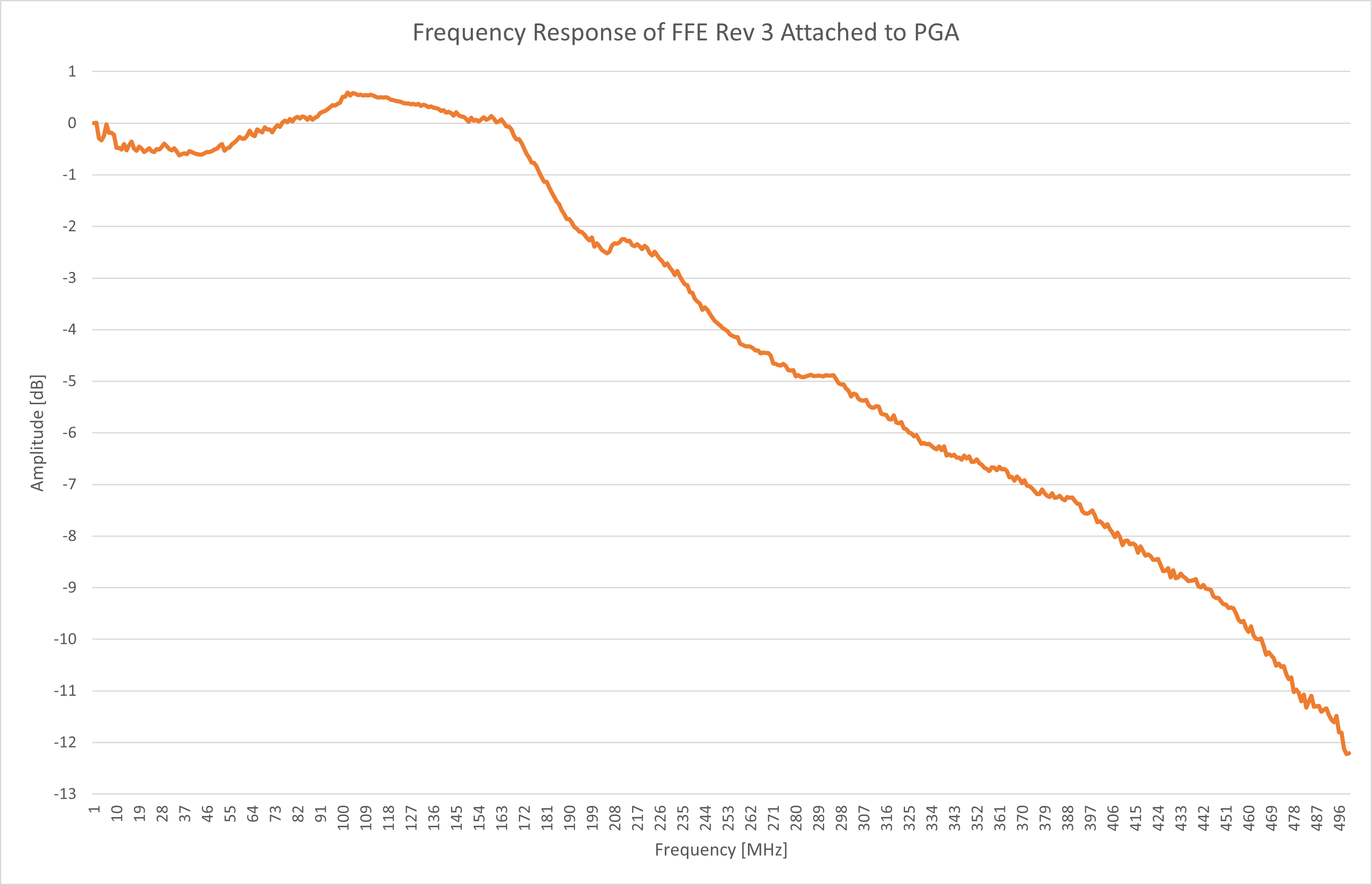








 Jithin
Jithin
 István Hegedűs
István Hegedűs
 Mark Omo
Mark Omo
any news about the project?