Yann Guidon / YGDES
Yann Guidon / YGDES-
Architecture update
04/02/2017 at 21:09 • 0 commentsA lot of progress was made in the last days ! In particular, the balanced tree system has been totally revamped in the log More balanced trees !
The "big picture" gets clearer and looks better than before. The basis is simple : pairs of bitplanes, one on each side of the backplane, each pair has a fanin of 8 for each address bit of the MUX16.
There are 6 address buses on the backplane :
- src/i : 3 bits
- src/sh : 3 bits
- dest : 3 bits
- DRAM/lines : 4 bits
- DRAM/col : 16 decoded bits (total : 256 words)
- DRAM/col aux : 16 decoded bits (for the 512 words version)
Still missing is the I/O system. By the way, what is this I/O thing and how is it implemented ?
About 500 relays are allocated to the I/O system. There is no parity so 16 boards are populated. When rounded up, this amounts to 512 relays/16=32 relays per bitslice, or 16 relays for the inputs and 16 relays for the outputs.
Inputs are easy ! It's just MUXes and 16 relays afford us 16 input words, which is more than enough (have you ever seen a microcontroller with 256 bits of inputs ?
-
More balanced trees !
04/02/2017 at 10:24 • 0 commentsAfter the craze of How to balance a fanout tree and Backplane routing considerations, I now need to make a single, large MUX (MUX32 for the address columns).
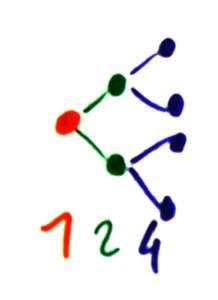
The relays create a fanout of 1, 2, 4, 8, 16 and this is getting annoying. So let's find a way to smooth this... Let's start with a simple binary tree for a MUX8:
![]()
As expected, the tree is logarithmic. But a simple permutation makes it more balanced :
![]()
That's better :-) Red and blue have just been swapped, between the lower and higher halves of the tree. Eeay !
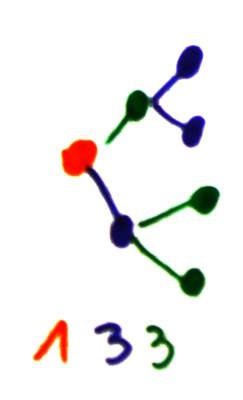
Now for something more complicated : a MUX16
![]()
That looks nice ! I simply took the previous tree and swapped the colors, between the high and low halves. Though it's not quite perfect... Because the color reversal won't work for a larger tree : I get 1-9-6-6-9 :-/
(the root is not considered because there is in theory nothing we can do about it)
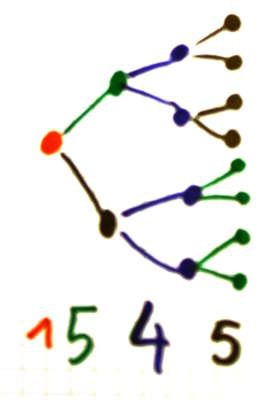
I got a better solution :
![]()
That's almost perfect !
The root MUX has a fan-in of 1 and the 4 other address lines have fan-in of 8 (and 2 resistors)
Now I'll see how I can include this technique in the other MUX of the system, to maybe ease the routing and shuffling of the address and register buses...
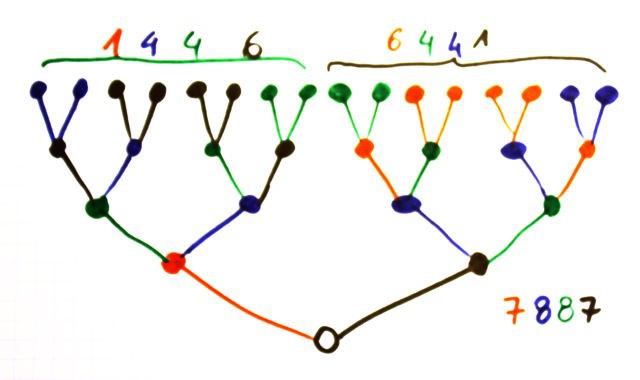
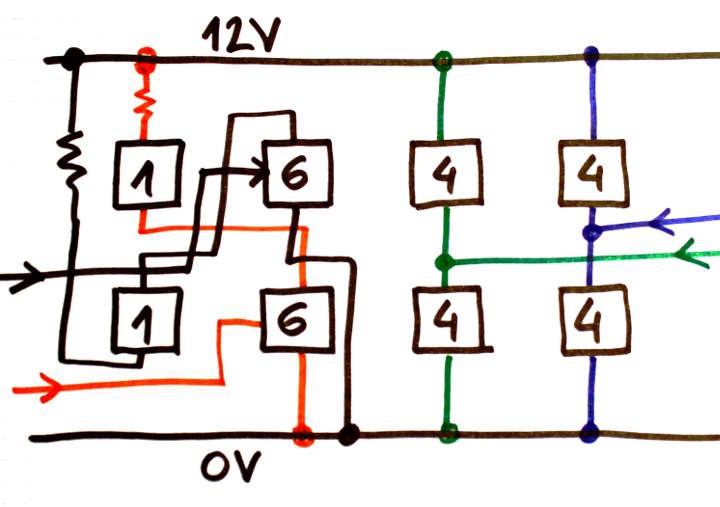
For the MUX16, things are pretty easy : take the two halves of the MUX32, and make two MUX16. Their combined weights are 7887 and you can connect green to green and blue to blue, you just have to swap red and black. Add two resistors and you're done.
![]()
Swapping some pins will makes the tracks even more easy to route !
What we get now is a very simple routing pattern that is repeated 9 times for each pair of upper/lower boards. The log Backplane routing considerations is now obsolete!
-
Structural sketches
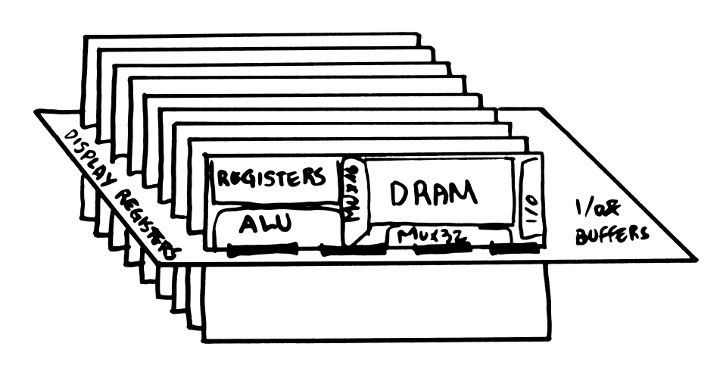
04/02/2017 at 07:13 • 0 commentsFor the "computational unit", I have designed this structure:
![]()
The spacing between boards is approx. 1 inch so 18 boards will make a 18 inches wide boards ! (round that to 20 inches for the extra space). It is possible to reduce this to about 10 or 12 inches by using both sides of the main backplane :
![]()
The bitslice boards are about 10cm tall and plug into the backplane with dual-row, 90° 0.1" pin headers.
Each bitslice has separate blocks : register set, ALU, memory. They are interconnected on the backplane to enable or modify certain functions:
- of the 18 ALUs, only 16 are used
- all the bitplane boards are identical but some are connected to make them work as parity bits
The memory is designed for 256 and 512 words. The "512" version is just an add-on and the bitplanes can receive one or two modules with 256 bits (and 16 relays) each.
The I/O is another story though.
-
New DRAM array
04/01/2017 at 20:31 • 2 commentsI just had the best idea of the last days, in the most unlikely place, but I'm not surprised anymore because that's the way progress happens : with cross-polination of ideas :-)
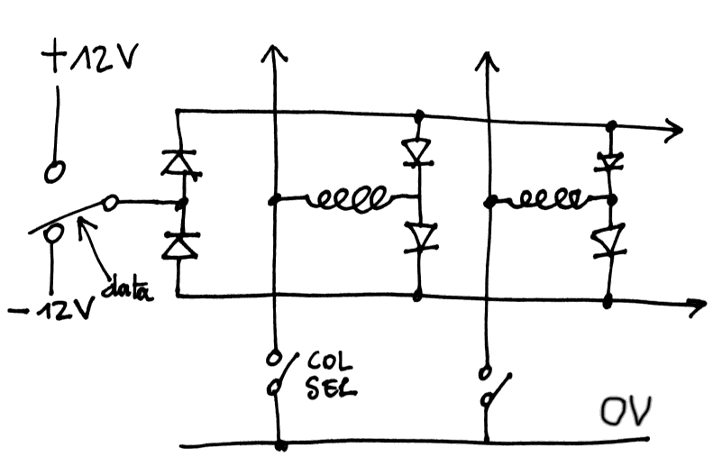
So I was returning to the #Dot flippers page and looked at the schematic of the arrays... The log Wild guesses contains some useful ideas, such as this image :
Everything is there ! This is the solution ! Just replace the coils with capacitors ! Diodes to the rescue !!!![]()
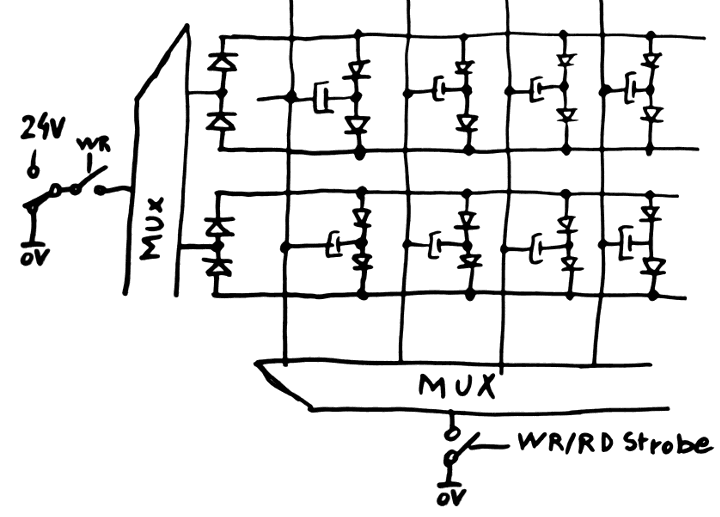
When the previous DRAM array circuit is rotated 90°, the circuit saves the large duplicated MUX that connects the diodes to 0V. After all, only one of them will conduct current.
The revised DRAM circuit is there :
![]()
The added diodes to the left increase the voltage drop but it's not significant. Their leakage though is critical.
The increase in diodes count is not significant but the saving in relays is great ! Less relays means less power consumption, fewer assembly hassles and less expensive...
So the number in the log Backplane routing considerations must be corrected.
- For 256 words: 2 MUX16=32 relays, or 576 relays for 18 boards
- For 512 words: MUX16+MUX32= 48 relays, or 864 relays
512 words is in the realm of possible but I'll start with 256 so I need "scalability"!
Wait !
Wait wait wait !
There's something else with the flip dot arrays : all the lines are driven simultaneously and only one column is active ! Could this be applied to our capacitor array ? If it is possible (without the gotchas that I was pointed to in the first iteration of the DRAM array) then I can save AGAIN a whole lot of relays and use only one MUX for all the columns ! I must test this ! If this holds true then
- For 256 words: 1MUX16=16 relays, plus another MUX16= 304 relays for 18 boards
- For 512 words: 1MUX16=16 relays, plus one MUX32=320 relays only !
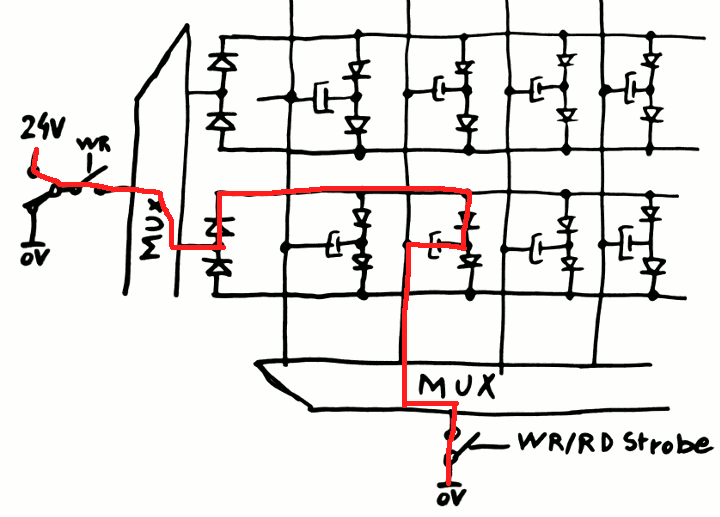
Following @roelh's comment, here are the (expected) current flows through the MUX and array:
Discharge:
![]()
Charge:
![]()
I hope it's clearer now :-)
Re-update: falstad simulation shows @roelh's concerns were justified... See https://hackaday.io/project/20864-ygrec-15-bis/log/56753-first-dram-array-prototype#discussion-list
-
Parity or not parity ?
03/30/2017 at 20:17 • 0 commentsFor such delicate mechanism, error detection is certainly necessary. It's the difference between a machine that (mostly) works and endless headscratching.
But things get pretty complicated...
First, how many parity bits ?
Parity is checked, stored and computed for each DRAM and register word, where they are vulnerable.
I thought about one parity bit, that's easy and simple, in theory. In pratice, it breaks the whole symmetry of the bitplane design, 17 is prime and partition is impossible.
The next number is 18 : it's even and has 3×3 as factor. It's better and I came up with some partitions to help reduce the strain on the address lines.
And 2 parity bits are better than one. For example one parity per byte, or a partial SECDED, will help discriminate where the error(s) occur(s).
But now I realise that going to 18 bitplanes breaks something else ! The CCPBRL system uses pairs of registers in strings, and 16 bitplanes works very well because 16=2×2×2×2, so we could "fanout" one signal to all 16 boards with 2 strings of 8 relays, controlled in the middle.
With 18 bitplanes, though, the numbers don't fall naturally : 18/2=9, and a string of 9 can't be tapped in the middle. Oh, with CCPBRL it's possible to have 4:5 strings but something else isn't good : a string of 9 coils requires 15V, which is "yet another voltage" to generate !
Thinking about it for a while, I realise that breaking the 18 in half wasn't the only solution. It's possible to partition it into 3 strings of 6 : 6 is even so can be cotrolled in the middle, and we get the necessary 9V between the 3V rail and the 12V rail.
The fanin-18 signals apply to all the circuits related to the parity-protected storages : memory and registers. There are not many of them (mostly write enable, read enable, etc.). More high-fanout signals are required by the ALU part, which is 16-bits wide and uses a pair of 8-coils strings.
2 bits of parity give more informations of the location of the fault.
Usually, the expected type of fault is a bad joint, a bad connector or a faulty part, like a leaky diode or capacitor. There could be power-related issues like voltage spikes that might trip one of the thousands of CCPBRL relays, so these issues are more diffuse. Having a consistent location to examine will help with the machine maintainance.
2 bits of parity can be used to check individual bytes : 2 independent groups of 9 bitplanes will protect one byte each. SECDED codes can't do better, and can't locate 2 simultaneous errors.
So the parity circuit is as simple as you'd imagine : XOR all the bits of a byte and compare the result with the parity bit...
-
Power-On routine
03/24/2017 at 04:19 • 0 commentsWorking with hysteresis logic is weird !
When you turn the machine on, you don't know the state of the outputs because they all default to off, which can be anything depending on the wiring, which is crazy because of all the interleaving.
For each logic level, the relays must be cycled to on and off to ensure that the state is reliable. For example, it means writing "all 1s" and "all 0s" to all 8 registers, which will also have the side effect of sending the addresses "all 1s" and "all 0s" to the data address decoders. The register read relays must also be exercised.
The "program" will certainly start with a few dozens of instructions that clear/set every bit, including status flags. To this end, going from "all 0s" to "all 1s" and vice versa can also exercise the adder, just add or subtract 1 to a register.
It will be interesting to find the shortest program that achieves that...
The power-on routine also requires all the parity bits to be in a legal state. This means scanning the whole memory and read/write data, first without halting the machine if a parity error occurs (which will occur because all the legal states have been lost), then a second run to check the machine has no fault.
The scanning can be done directly with the refresh circuitry (a simple LFSR and arbitration logic). We just need to count how many times the LFSR has wrapped around:
- cycle of 256/512 access, write all 1s while disabling parity checks (but write parity
- cycle, read the 1s, write all 0s and check parity
- cycle, read the 0s
The LFSR can also generate addresses for the register set and the ALU control lines. When the cycle counter reaches 4, the machine can start fetching instructions.
Considering a cycle rate of 25IPS, a 256-words machine will take around 10 second per cycle, or 30s to fully scan the memory 3 times. With 512 words, the power-on routine takes one minute...
-
CC-PBRL : Magnetic hysteresis and fanout
03/17/2017 at 06:34 • 0 commentsI'm still investigating CC-PBRL (theoretically, these days, but I'll resume practical experiments ASAP).
One unanswered question is a bit puzzling : What is the duration of retention of data stored into a relay coil ?
The magnetic hysteresis is not controlled by the electrical parameters, at least as long as the hysteresis works. It takes energy to reverse the stored magnetic flux so I consider the retention "long". But I have not measured it.
What are the causes of loss of magnetic flux ? As far as I know, the only cause of dissipation is when the core reaches the Curie temperature, which is unknown for this relay.
Another probable cause of "erasure" would be "magnetic interference" : just as a magnetic tape can be erased by subjecting it to high frequency magnetic fieds oscillations, neighbouring relays could affect a coil. After all, they are packed pretty close to each others. The relay's metallic can might help shield the coil but I think it's aluminium (must be verified) which is not a magnetic insulator. At least a magnet doesn't seem affected by the can's material.
Part of the answer might be found in the characteristics of "core memory" arrays, so I am asking my fellows HaDers if they can find estimates of data retention lengths of commercial core planes :-) Does this retention vary a lot at ambient temperature ?
The other question is : how to deal with fanout ?
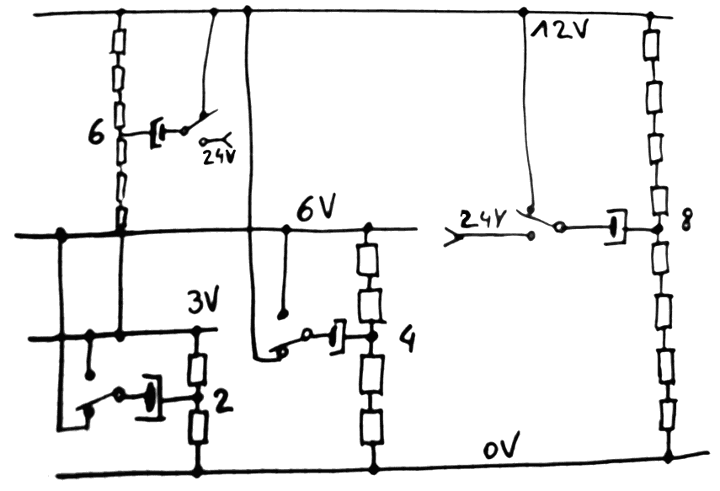
One way to deal with high-fanout circuits is to increase the voltage so I have now two domains : 3V and 12V (with their respective 2x supplies because electrolytic capacitors need their own bias). But what about the cases where more than 2 (3V) or 8 (12V) relays are needed ?
For the case of 4 relays, there is a solution : use the intermediary 6V rail that is required for the 3V domain, and bias it with the 12V rail. This might be "a bit noisy" though but it solves the problem with no added parts.
The case of 6 relays is rare but 6=8-2 so the string of 6 coils can be connected between the 3V and 12V rails, and biased by the 24V rail.
![]()
But there are many control signals that require much more than a fanout of 8. Strings of 8 must be parallelled, which brings the question of how to connect them together.
It is possible to create even longer strings, powered with 24V supplies, but then a bias of 48V is required. And even then 16 coils in series is still not enough so why not use the 48V supply ? This would never end, if you follow this logic, and ever higher voltages get used, increasing the stress on the poor coupling capacitors. My stock has 16V and 25V capacitors and I don't want to buy 63V ones...
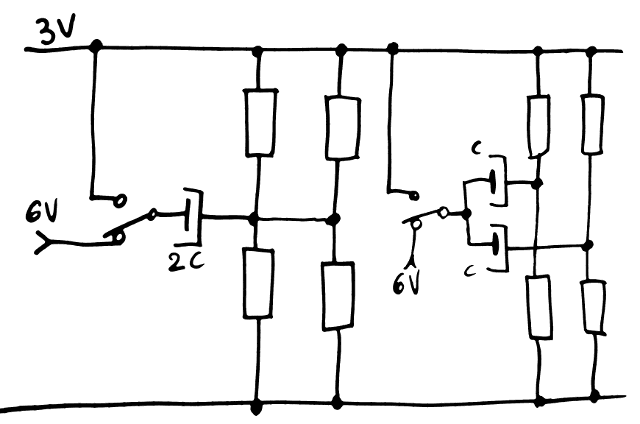
![]()
So paralleling is required. There are two solutions : either with shared capacitor, or individual capacitors.
One thing is obvious from this diagram : for a shared capacitor, the capacitance increases with the number of strings. We would rather keep a single capacitor value so the capacitors would be in parallel. This reinforces the case of the individual capacitors.
Another factor is how tying strings in the middle will affect the electrical properties, particularly with temperature drift. The shared capacitor will "average" the characteristics but is it a good thing ? Will this affect data retention times ?
For now, I lean toward the "separate capacitors" version : it's simple, reliable, but hasn't been tested yet.
The question now is the current handling : more strings means more current through the relay's contact. Fortunately the capacitor blocks DC so the relay can easily switch from one state to another without a risk to get "stuck". This proves that CC-PBRL is much better than the resistor-coupled PBRL :-) (Just make sure you have ample and adequate decoupling everywhere)
-
Output TTY
02/18/2017 at 13:00 • 8 commentsI've been much less active lately for very good reasons, the most important being to renovate my whole workshop. I Had to let go of quite a lot of old gears but I found some "forgotten treasures" though (it's always a matter of perspective, of course).
One of them is a Sinclair SP200 dot matrix printer with the standard Centronics interface. 8-bits glory and shipped with the internal schematics and protocol ! What better peripheral output could I have ? I even have a stack of continuous paper for it...
I haven't tested it yet but it was bought around 1990 and I remember having to source a new ribbon in the mid-90s. Today the ink is certainly dry...
Who can help me rejuvenate the ink ribbon ?
-
Dual Diodes (the hard way)
12/18/2016 at 00:27 • 8 commentsUpdate 20170404: superseded by New DRAM array
I have received "some capacitors" as well as "some diodes". The surface-mount LL4148 were meant for program wiring but the little gotcha with the DRAM made them even more important for temporary data storage.
I have to redesign the capacitor arrays and these diodes are pretty critical because they consume a bit more of PCB real-estate. Oh and they can be very tricky to solder.
I have chosen to save a bit of surface with a little naughty trick : solder them back-to-back, sharing a PCB pad. This saves maybe 2mm in one dimension and should not affect reliability. This means I have to redraw a new part in Eagle...
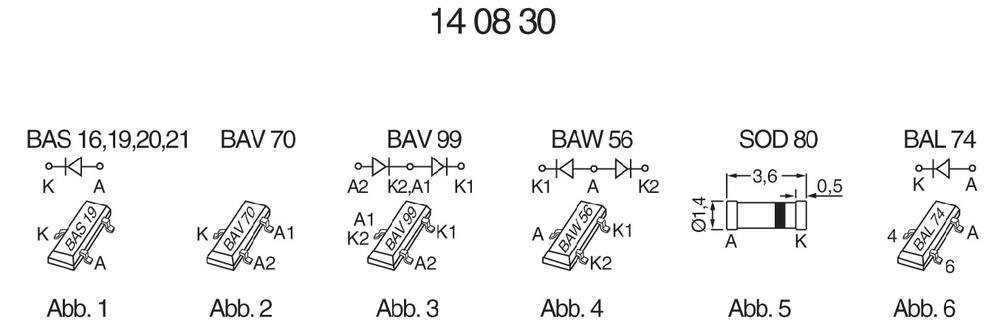
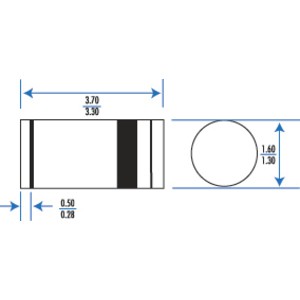
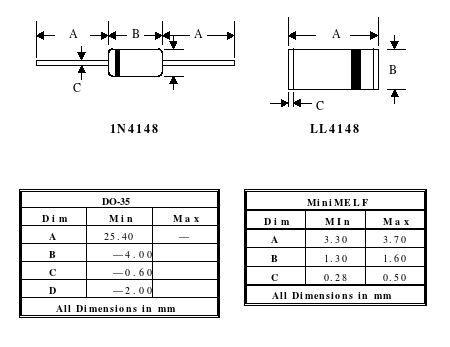
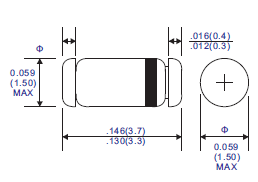
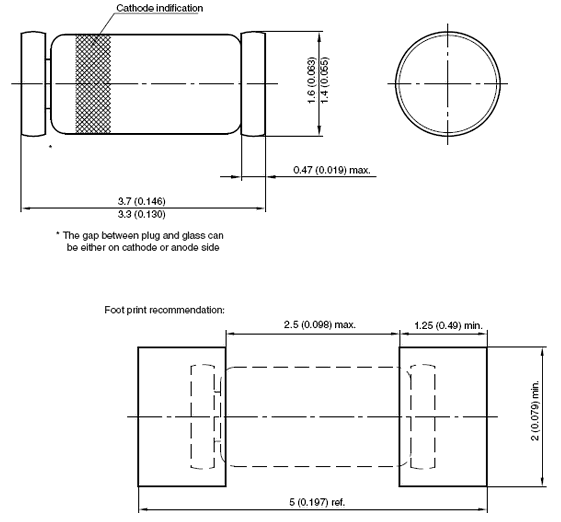
Let's have a look at the specs of the chosen packaging (I have actually "chosen" the lowest bidder, to be honest, not minding the increased soldering efforts).
![]()
![]()
![]()
![]()
![]()
![]()
![]()
I'm trying to determine the agreed upon miniMELF/DO35/SOD80/LL34 (pick your favorite) packaging dimensions. Most people use the 3.3-3.7mm length...
The last screenshot shows the recommended footprint. My idea is to merge one pad with the pad of the neighbour diode. Normally, there would be at least 2×5mm but the merge saves 1.25mm, giving a length of 8.75mm. This is still quite long, longer than the capacitor's diameter. Routing will be fun.
Another approach would be vertical soldering. Density certainly increases, as well as other kinds of headaches. I could make a tool to keep the diodes upright during soldering but the next step (connecting all the leads in the air) is less deterministic...
Through-hole parts create their own kinds of problems. When space is constrained, the hole uses space on both PCB layers, but this area might be precious or critical on one side, for routing stakes.
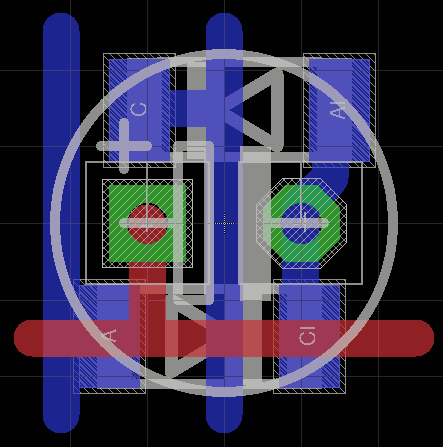
My current idea is to create a "part" in EAGLE with the capacitor and the two diodes, and rotate every other by 180° to fit everything in the 6mm grid... Hoping it will fit...
I have DRAM capacitors (25V 100µF) both in 5×11 and 6×7mm formats. Both seem happy with 0.1" spaced through holes. That's a good starting point for the new composite part.
So I created this symbol:
![]()
The footprint is constrained by the size of the capacitor :
![]()
I have chosen a grid of 6.35mm (1/4") which is a tiny bit larger than the 6mm of the previous attempt. It shouldn't be too hard to solder manually. I have given up on trying to solder the diodes back to back, the above pattern is easily integrated as an array:
![]()
Just put the cells close to each other, snapping on the grid, and voilà.
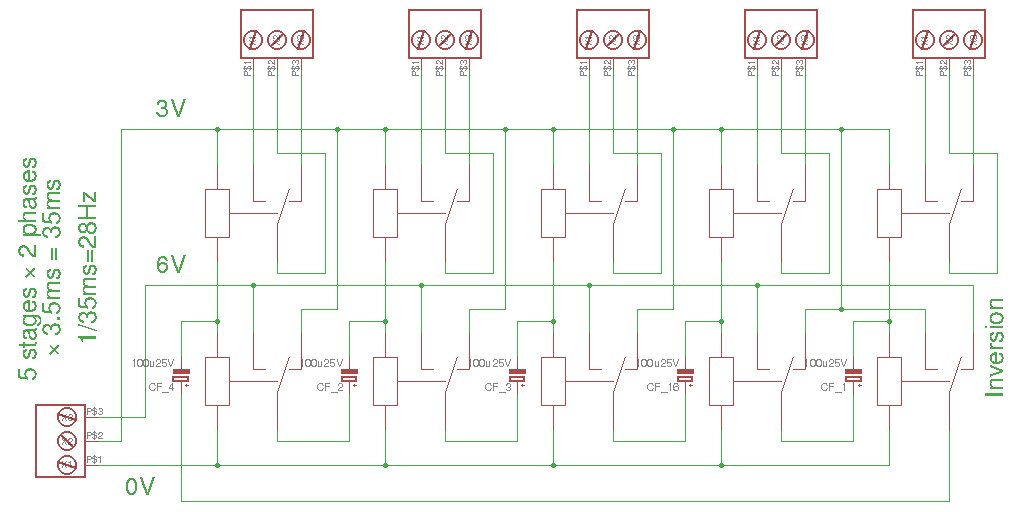
I have tried a 16×32 array, which is a bit larger than 10×20cm (without the mux16 and connectors). The total capacity with 16+1 slices is 512 words, or 8Ki bits, or one kilobyte. I might postpone the soldering of all the parts... Because of the "screen", initially I need maybe 64 words at first (4 columns, 1K capacitors).
In theory, I can drive all the vertical wires of all the boards with a single 64-mux, the total relay count is therefore: 64+ (16×17)=336. Add to this the refresh logic, the data and address MUXes, the sense and buffers, and the DRAM system uses about 500 relays as expected...
Some questions remain :
- are there any more gotchas I have to care about ?
- I have "solved" the partition of the MUX16, is there a solution for MUX32 ?
- how long will the capacitors keep enough charge with the couple of diodes ? I suspect that a higher leakage will affect the refresh cycles. 512 words at 10 refresh per second (optimistic average) means that the whole array is refreshed every minute...
This can be answered with a magic circuit called a prototype ;-)
-
Clock generator
12/05/2016 at 01:21 • 2 commentsI'm starting easily with this simple circuit that I should finalise ASAP.
It's just another ring oscillator, with another twist. It now uses a dual power supply, capacitor coupling, and the second relay drives external signals. It's a "full" CC-PBRL system where the output's load will not disturb the frequency. It also helps a lot with the fanout.
![]()
Then, the LFSR will be quite similar, but with an added charge pump.
YGREC16 - YG's 16bits Relay Electric Computer
Fork of #AMBAP, here I discuss about the physical implementation of the bitslice architecture with russian РЭС15 (see what I did here?)