 Zapp
ZappBADGE HARDWARE SPECS
- Rigado BMD-300 SoC
- Nordic NRF52, ARM Cortex M4F
- Blast Processing
- 512kb flash, 64kb ram
- Integrated Antenna
- 128x128 1.44” color LCD
- 19 FPS video over 8 Mhz SPI bus (and maybe m0ar?)
- Middle-Out Compression
- 15X WS2812B LEDs AKA “Neopixel”
- Tilt and Ambient light sensors
- 30% better power management (so far 30mA draw during Bling mode)
- Micro SD Card
Note: Prototype displayed has test points and soldered headers. The final version will not have test points or JTAG headers, but the footprint will exist. Also the actual components are subject to change by final production, equivalent functionality, but we may find improvements which require a swap (e.g. in our KS video we show APA102C Dotstar LEDs, and we decided to go with the NeoPixels instead).
BADGE FUNCTIONS
- 2820 Bling Modes & Bring Your Own Bling (BYOB)
- Many Games: CHIP8 & SuperCHIP Emulation support for over 64 ROMS
- Booz3 Hacking
- TCLish Scripting Control of the Hardware
- Smartphone Integration
- Badge to Badge Game
WHO:: We are 5 dudes from California with backgrounds in HW and SW engineering. We enjoy building and hacking things for fun. AND!XOR pronounced..."AND-NOT-EX-OR"...
WHAT:: We built a hackable, open badge for use at DEFCON 25 in Las Vegas and any other conferences in the future. The badge also serves as a dev board for hardware developers of any experience level from novice to expert sorcerer.
WHY:: The purpose is to put some really awesome hardware around the necks of a bunch of hackers and see what they come up with. We hope to encourage others to make use of the badge and come back with their own flavor in years to come, AND to promote embedded development across the community.
HOW:: Pure internet science. We've developed algorithms which calculate the spin rate of cat quarks for generating our ssh keys at a rate of (P+9)/((# of blackberry users)^2), where P is the probability that a cat will leave a house when a door is opened for them.
WHERE:: Caesars Palace, Las Vegas
WHEN:: July 27th - July30th, 2017
EXTRAS:: We are spending our free time and money outside of our busy work schedules to develop this from 3 separate locations across California. So we are definitely open and encourage feedback, suggestions, and features to be added onto the badge. If you complain that there are not enough blinky's happening then you are welcome to build your own. Feel free to Leave your comments below if you have questions, concerns, comments, philosophical statements, haiku's, or send us a tweet...that works too.
Twitter:: Check out AND!XOR, our official twitter account on twitter for daily and often hourly updates of the badge process.




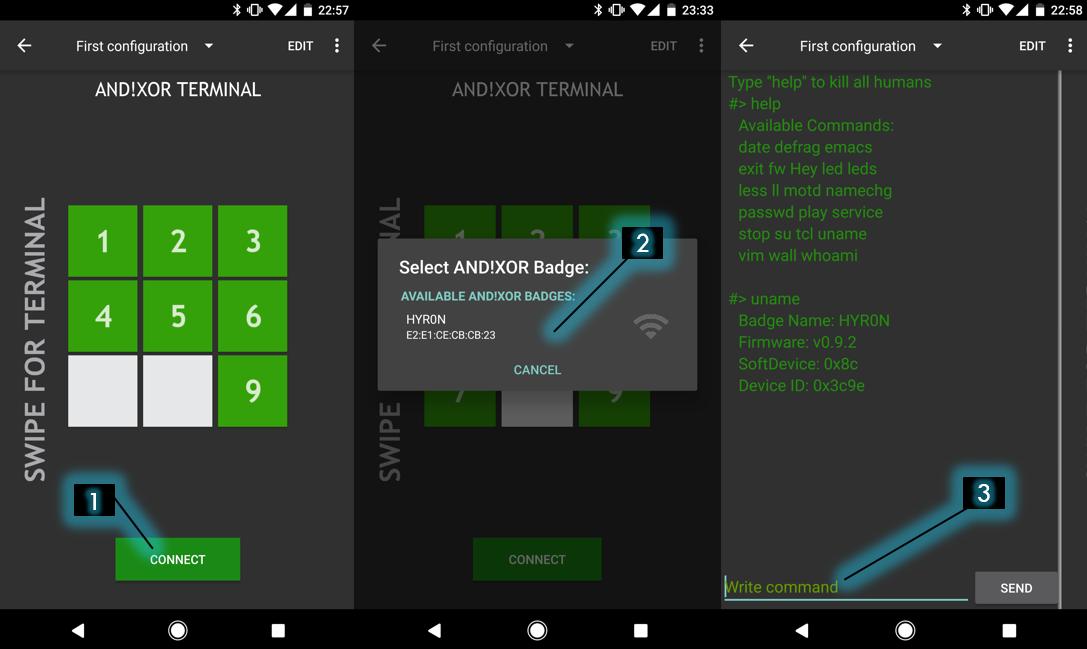
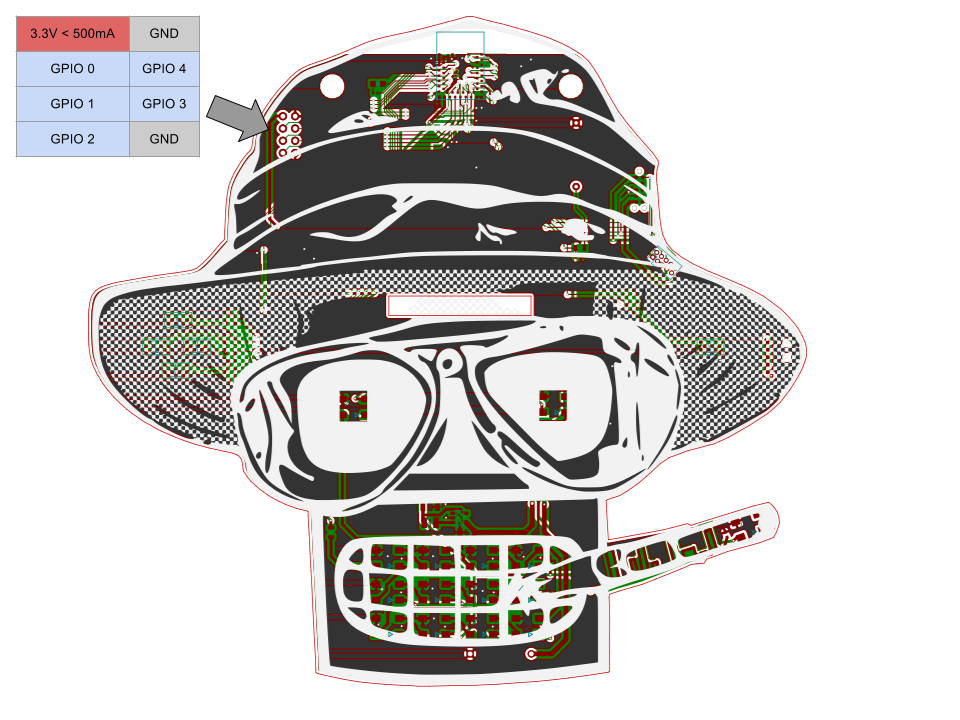
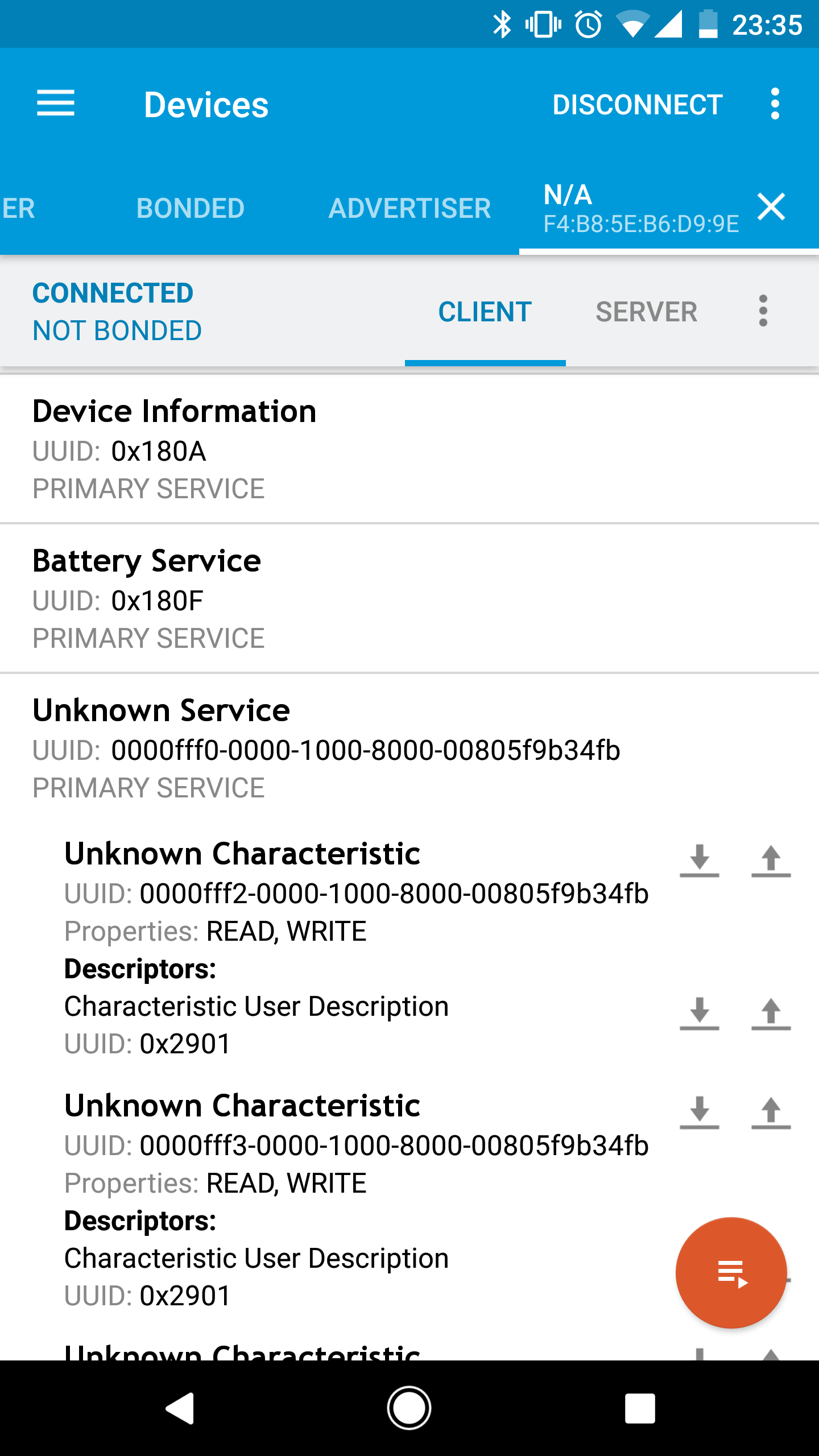
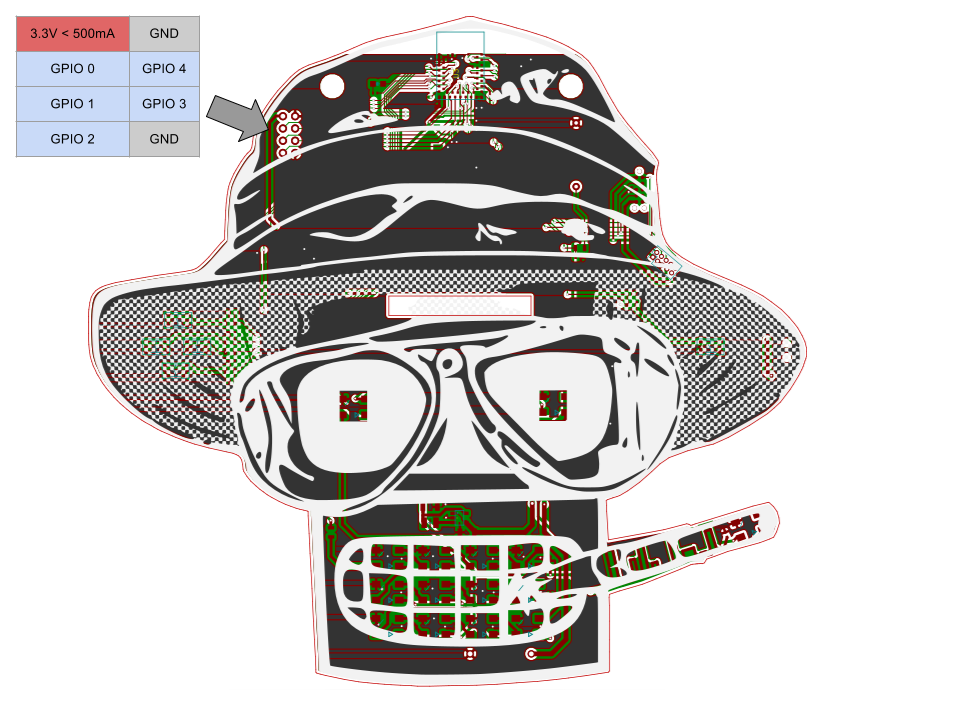 Basic GPIO io_read and io_write commands have been implemented. The PCB has a total of five IO exposed. This was all that was left after all the bling was done. Each IO is referred to as 0 through 4 in the TCL code. Note 3.3v power is also provided for addons if you desire.
Basic GPIO io_read and io_write commands have been implemented. The PCB has a total of five IO exposed. This was all that was left after all the bling was done. Each IO is referred to as 0 through 4 in the TCL code. Note 3.3v power is also provided for addons if you desire.
















 Benchoff
Benchoff
 Roger
Roger
Hi
Nice to meet you after viewing your profile i am Jacinda, from (jakarta) indonesia,
i have a project discussion with you please email me on: (jacinda.seiler@yahoo.com)