 Pavel
PavelComputer design goals:
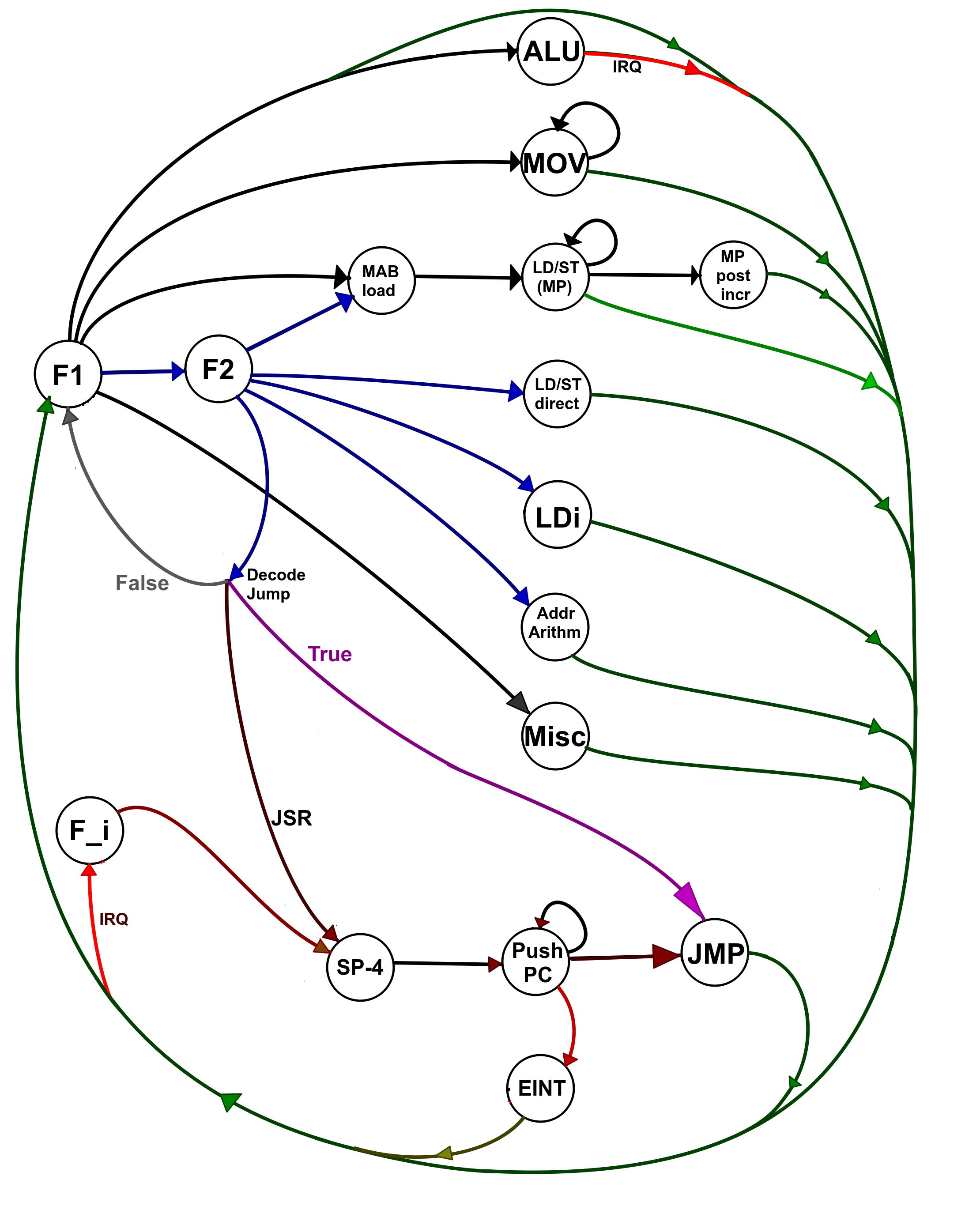
Architecture:
RISC-like – inspired by MIPS, but is quite different. This is Load/Store architecture, meaning that ALU operations are only applied on data in registers, and for using data from memory it should be first loaded to these registers, or stored from them back to memory, in separate instruction cycle.
The instruction set is presented in its own sub-project.
The assembly language is presented also in ints own sub-project.
16-bit computer, 16-bit wide registers, 16-bit wide ALU and 16-bit bus.
Memory consists of 16-bit words.
Up to 4G bytes can be addressed in theory, by 32-bit addresses, byte-addressable memory. (Although most memory transfers would be word-sized). In real machine, no more than 16 MBytes of SRAM will ever be installed.
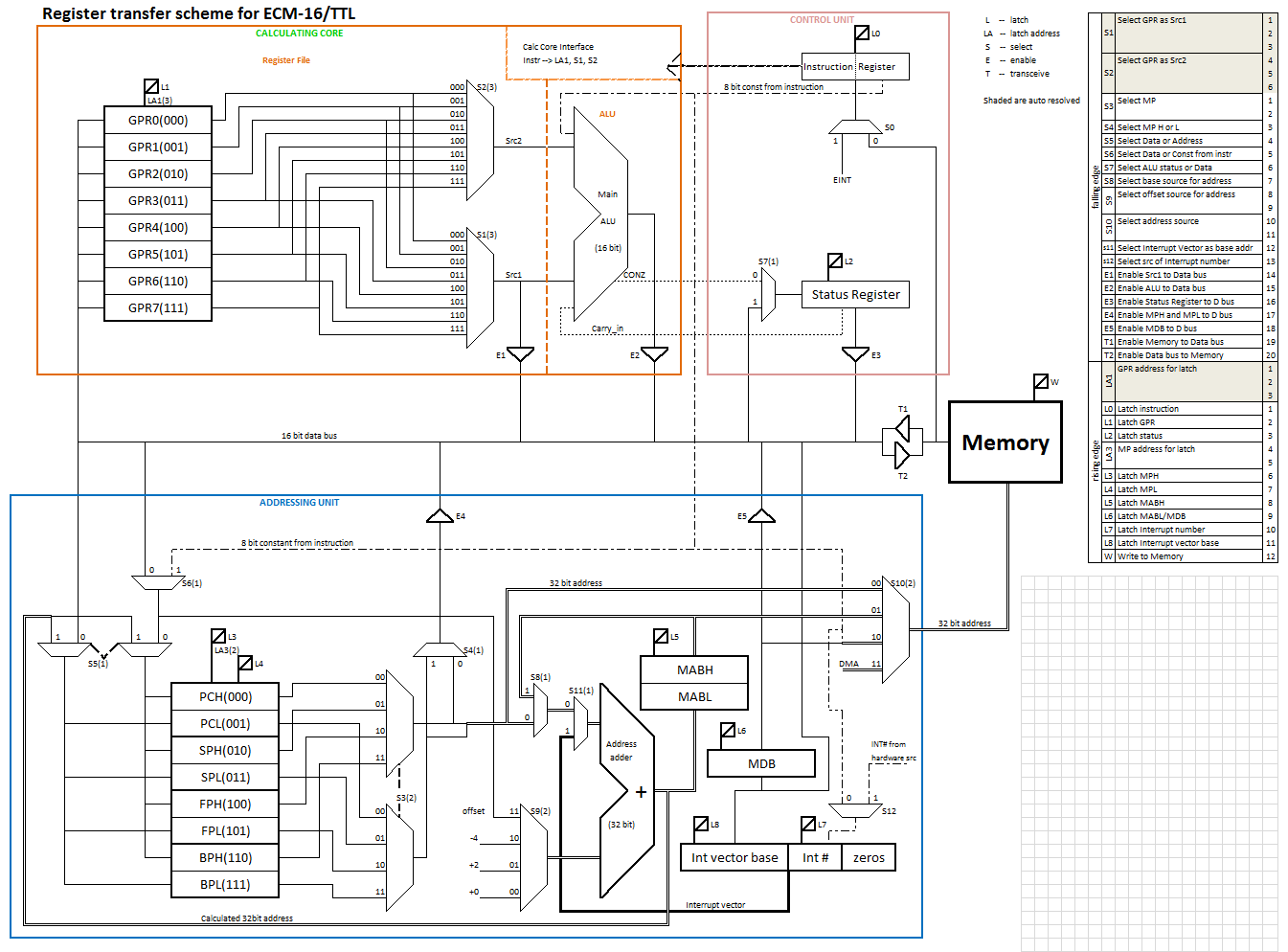
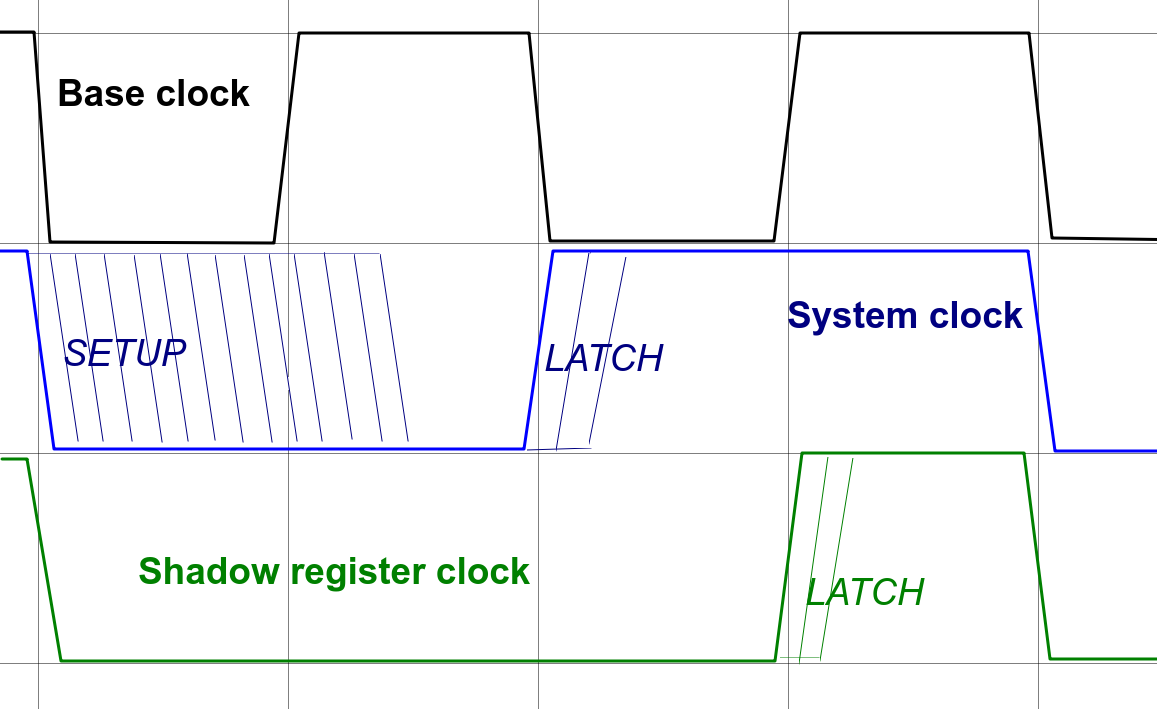
Register transfer scheme:
Component base: 74HCxx SSI and MSI chips (Elementary logic, multiplexers, flip-flops, 8-bit registers, and counters).
Input-output (tentative):
Input: keyboard.
Output: Monitor (VGA): characters, pseudographics, bitmap.
Mass storage: 1GB CompactFlash card through Parallel ATA interface.
Registers:
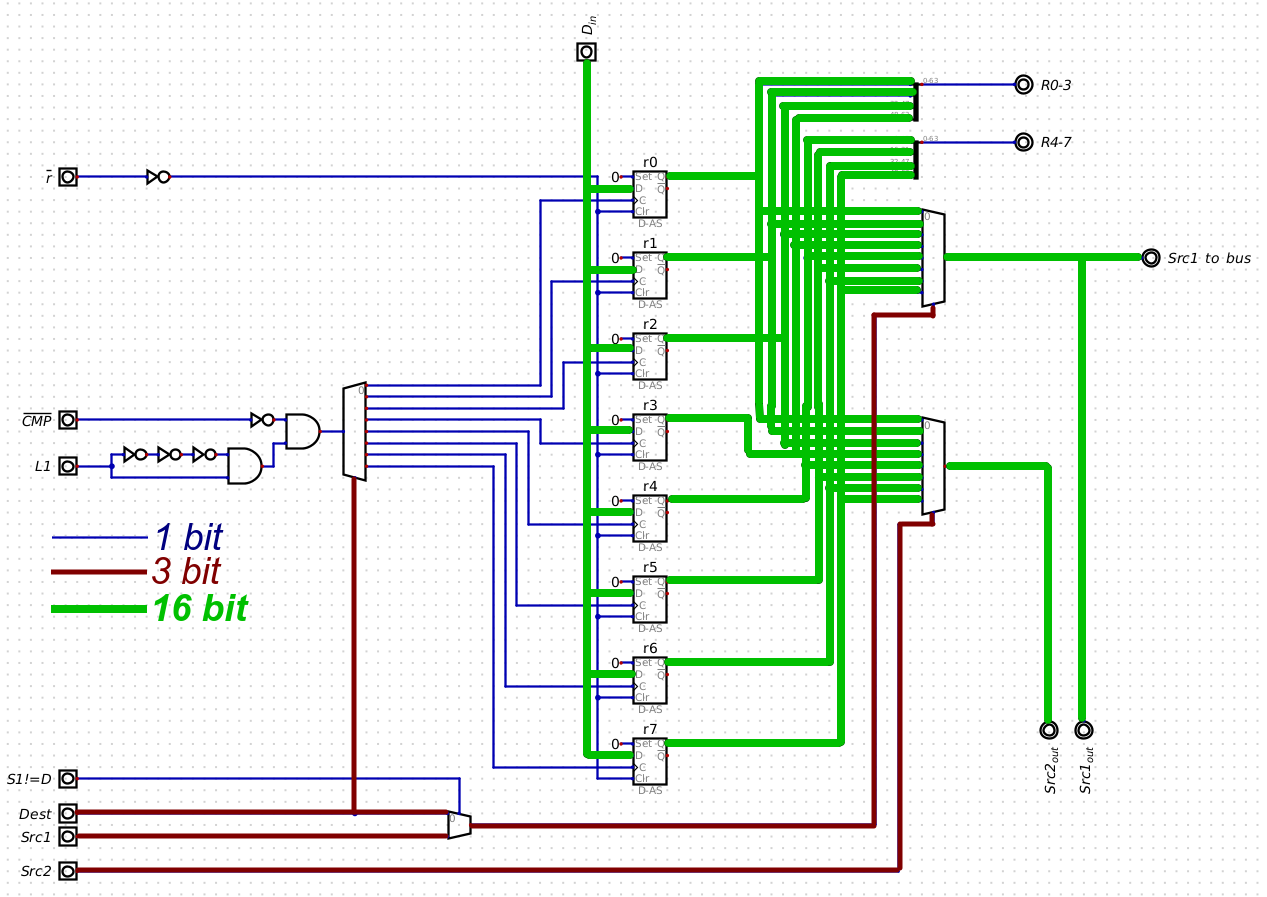
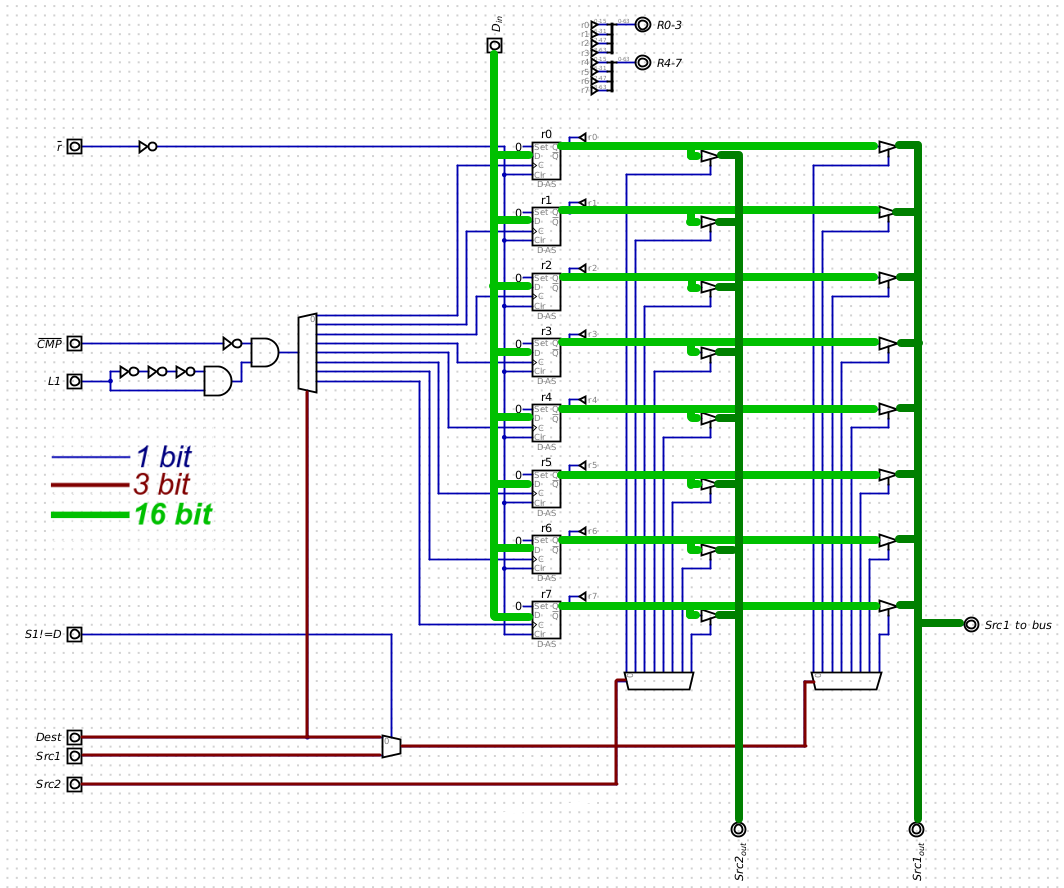
Register file: 8 16-bit registers, 3-address:
First address (A operand) is written with result of ALU operation on 2 registers (B and C operands). ;
Some ALU ops use only 1 register, as accumulator;
Memory Pointers: 8 16-bit registers paired to yield Program Counter, Stack Pointer, Frame Pointer and Base Pointer (all 32-bit);
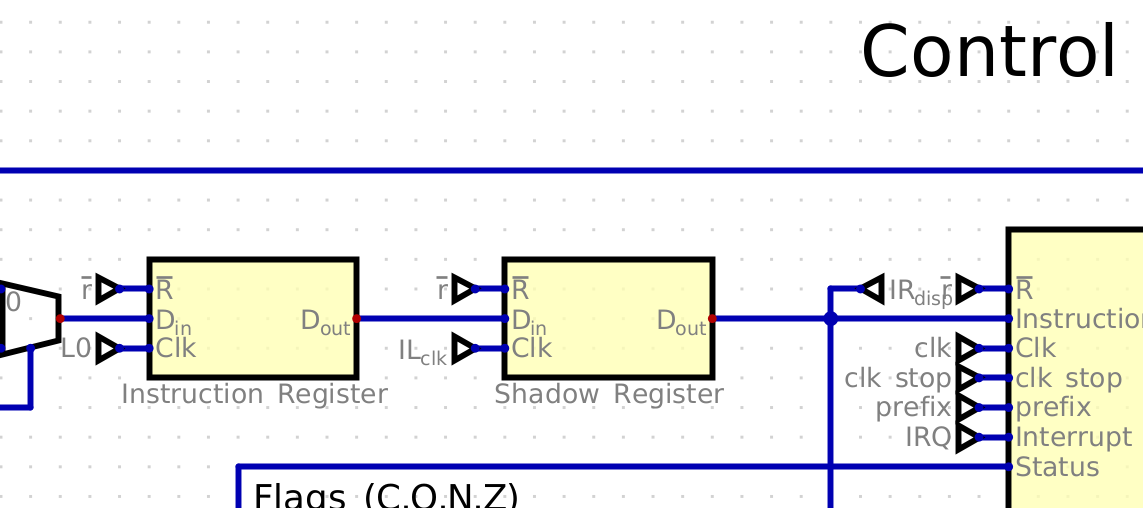
Instruction register: 16-bit, holds running instruction;
Memory Data Buffer: 16-bit, holds additional data for some instructions;
Memory Address Buffer: 32-bit, holds result of Address Arithmetic Unit;
Interrupt Vector: 32-bit, holds address of Interrupt Service routine start, 2 parts: 16-bit Interrupt Vector Base (high word) and 8 bit Interrupt Vector address, second least significant byte, loaded when entering interrupt, the least significant byte is always zero;
Status Register: 4-bit, holds Main ALU output flags.
Functions: ADD, SUB, AND, NOR, XOR, SHIFT, ROTATE
B operand modifications: no, invert (1-complement), twos complement, replace with: 0, 1-255.
ALU Adder: fast adder (16-bit, with carry look-ahead) for high speed.
Memory Addressing:
Several different addressing modes are to be supported: Immediate, Direct, Indexed, Indexed with pre-increment and Indexed with post-increment.
Address Adder ( 32-bit, with carry look-ahead ), included into Address Arithmetic unit, which adds signed offset to Memory Pointer for indexed address calculation.
ALU together with register file are built, and assembled into the Calculating core. Its testing is described in more detail in its own project.



 Ed S
Ed S

 kaimac
kaimac
Have you considered using a 74HC283 4 bit full adder with carry lookahead? Or do you want to implement the adder at the gate level? Using 4 bit or 8 bit wide parts would make the schematic simpler to read and the board easier to build.